

 “Context is everything,” or so the saying goes, which may be why artificial intelligence has a long way to go to in order to match, let alone replace, human intelligence. While computer vision researchers have made impressive advances in image recognition, the ability to not only identify objects but recognize situations and predict what will happen next is still the preserve of humans.
“Context is everything,” or so the saying goes, which may be why artificial intelligence has a long way to go to in order to match, let alone replace, human intelligence. While computer vision researchers have made impressive advances in image recognition, the ability to not only identify objects but recognize situations and predict what will happen next is still the preserve of humans.
Researchers at UW CSE and the Allen Institute for Artificial Intelligence (AI2) are trying to help computers make that leap from content to context with the development of the ImSitu situation recognition tool. The New York Times published an article today examining the present limitations of computer vision in application such as self-driving cars — and took ImSitu out for a spin.
From the article:
“Today, computerized sight can quickly and accurately recognize millions of individual faces, identify the makes and models of thousands of cars, and distinguish cats and dogs of every breed in a way no human being could.
“Yet the recent advances, while impressive, have been mainly in image recognition. The next frontier, researchers agree, is general visual knowledge — the development of algorithms that can understand not just objects, but also actions and behaviors….
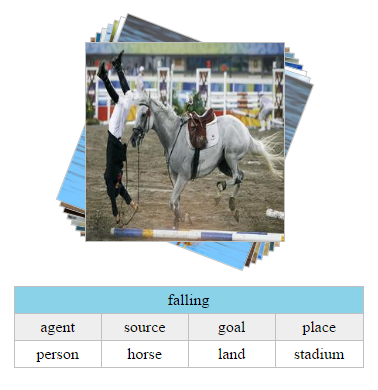
“At the major annual computer vision conference this summer, there was a flurry of research representing encouraging steps, but not breakthroughs. For example, Ali Farhadi, a computer scientist at the University of Washington and a researcher at the Allen Institute for Artificial Intelligence, showed off ImSitu.org, a database of images identified in context, or situation recognition. As he explains, image recognition provides the nouns of visual intelligence, while situation recognition represents the verbs. Search ‘What do babies do?’ The site retrieves pictures of babies engaged in actions including ‘sucking,’ ‘crawling,’ ‘crying’ and ‘giggling’ — visual verbs.
“Recognizing situations enriches computer vision, but the ImSitu project still depends on human-labeled data to train its machine learning algorithms. ‘And we’re still very, very far from visual intelligence, understanding scenes and actions the way humans do,’ Dr. Farhadi said.”
UW CSE Ph.D. student Mark Yatskar and professor Luke Zettlemoyer worked with Farhadi on ImSitu, which the team presented at the Computer Vision and Pattern Recognition conference (CVPR 2016) in June.
Read the full article here, and check out the Times’ results using ImSitu here.
Try ImSitu for yourself here, and read the research paper here.