

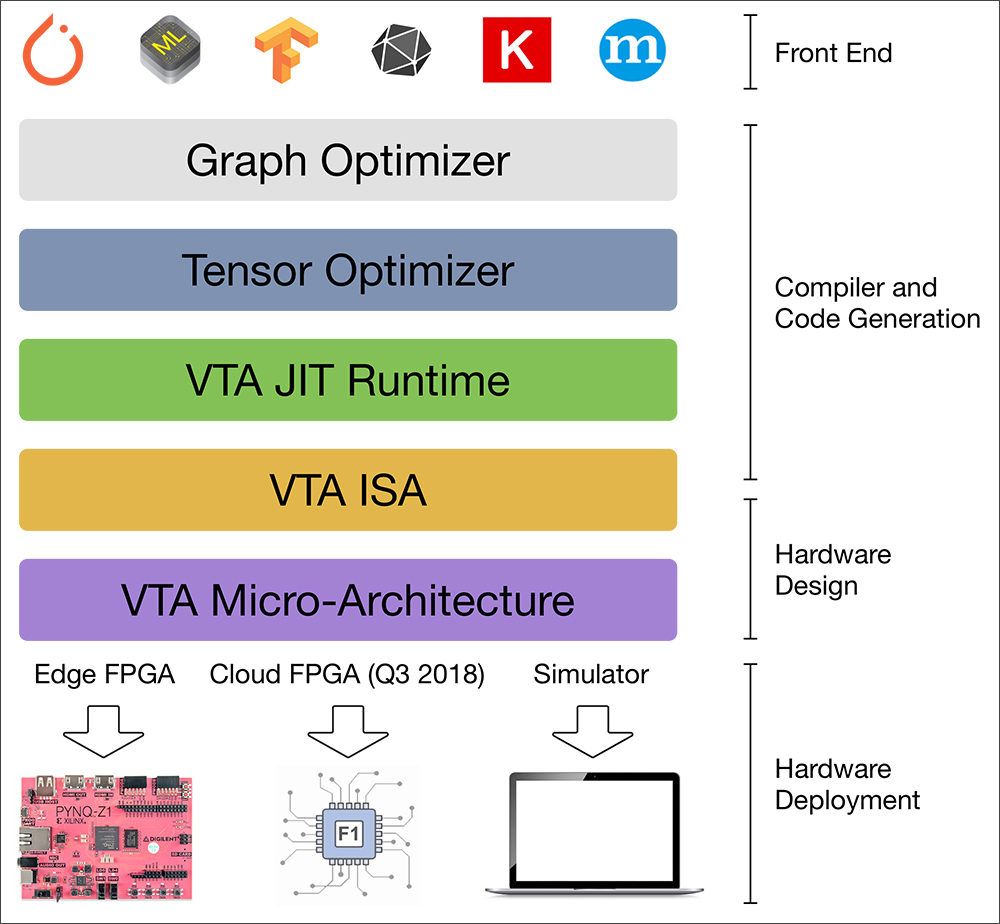
The VTA open-source deep learning accelerator completes the TVM stack, providing complete transparency and customizability from the user-facing framework down to the hardware on which these workloads run.
A team of Allen School researchers today unveiled the new Versatile Tensor Accelerator (VTA), an extension of the TVM framework designed to advance deep learning and hardware innovation. VTA is a generic, customizable deep-learning accelerator that researchers can use to explore hardware-software co-design techniques. Together, VTA and TVM offer an open, end-to-end hardware-software stack for deep learning that will enable researchers and practitioners to combine emerging artificial intelligence capabilities with the latest hardware architectures.
VTA represents more than a stand-alone accelerator design by incorporating drivers, a JIT runtime, and an optimizing compiler stack based on TVM. It offers users the option to modify hardware data types, memory architecture, pipelining stages, and other factors for a truly modular solution. The current version also includes a behavioral hardware simulator and can be deployed on low-cost, field-programmable gate arrays (FPGAs) for rapid prototyping. This potent combination provides a blueprint for an end-to-end, accelerator-centric deep learning system that supports experimentation, optimization, and hardware-software co-design — and enables machine learning practitioners to more easily explore novel network architectures and data representations that typically require specialized hardware support.
“VTA enables exploration of the end to end learning system design all the way down to hardware,” explained Allen School Ph.D. student Tianqi Chen. “This is a crucial step to accelerate research and engineering efforts toward future full-stack AI systems.”
The benefits of VTA can be extended across a range of domains, from hardware design, to compilers, to neural networks. The team is particularly interested to see how VTA empowers users to take advantage of the latest design techniques to fuel the next wave of innovation at the nexus of hardware and AI.

The team behind VTA, left to right, from top: Tianqi Chen, Ziheng Jiang, and Thierry Moreau; Luis Vega, Luis Ceze, and Carlos Guestrin; and Arvind Krishnamurthy.
“Hardware-software co-design is essential for future machine learning systems,” said Allen School professor Luis Ceze. “Having an open, functioning and hackable hardware-plus-software system will enable rapid testing of new ideas, which can have a lot of impact.”
In addition to Ceze and Chen, the team behind VTA includes Allen School Ph.D. students Thierry Moreau and Luis Vega, incoming Ph.D. student Ziheng Jiang, and professors Carlos Guestrin and Arvind Krishnamurthy. As was the case with the original TVM project, their approach with VTA was to engage potential users outside of the lab early and often — ensuring that they not only built a practical solution, but also cultivated a robust community of researchers and practitioners who are shaping the next frontier in computing. This community includes Xilinx, a leader in reconfigurable computing, and mobile technology giant Qualcomm.
“Xilinx Research is following TVM and VTA with great interest, which provide a good starting point for users who would like to develop their own deep learning accelerators on Xilinx FPGAs and integrate them end-to-end with a compiler toolflow,” said principal engineer Michaela Blott.
“Qualcomm is enabling Edge AI with power-efficient AI processors,” said Liang Shen, senior director of engineering at the company. “We are excited with such an open deep-learning compiler stack. It will help to establish a win-win ecosystem by enabling AI innovators to easily deploy their killer applications onto any AI-capable device efficiently.”
“We’re excited to see the start of an open-source, deep learning hardware community that places software support front and center,” Moreau said, “and we look forward to seeing what our users around the world will build with VTA and TVM.”
To learn more about VTA, read the team’s blog post here and technical paper here, and visit the Github repository here. Read more about team’s previous work on the TVM framework here and the related NNVM compiler here.