


Misinformation can spread like wildfire on social media, fueled in part by platforms’ tendency to prioritize engagement over accuracy. This puts the onus on individual users to determine the veracity of posts they see and share on their feed. Likewise, when it comes to violence, profanity and other potentially harmful content, users are often left to fend for themselves in the face of indifferent or inadequate moderation. The current state can make social media platforms a harrowing place — particularly for members of marginalized communities.
Researchers in the University of Washington’s Social Futures Lab led by Allen School professor Amy X. Zhang hope to change that by designing social media tools that empower users while minimizing the burden of managing their online experiences.
“A big problem to me is the centralization of power — that the platforms can decide what content should be shown and what should get posted to the top of one feed for millions of people. That brings up issues of accountability and of localization to specific communities or cultures,” Zhang explained in an interview with UW News. “I’ve been looking at what it would mean to decentralize these major platforms’ power by building tools for users or communities who don’t have lots of time and resources.”
At the 26th ACM Conference on Computer-Supported Cooperative Work And Social Computing (CSCW 2023) last month, Zhang and her co-authors shared promising results from two such projects: an exploration of provenance standards to help gauge the credibility of media, and the creation of personal moderation tools to help stem the tide of harmful content.
Seeing is believing?

The proliferation of misinformation on social media platforms has led to a “credibility crisis” when it comes to online content — including that posted by local and national news organizations. Visual content, in particular, can be used to manipulate users’ understanding of and reaction to events. While reverse-image search allows users to investigate potentially problematic content, this approach has its limitations; the results are often noisy or incomplete, or both.
Lab member Kevin Feng, a Ph.D. student in the UW Department of Human Centered Design & Engineering, believes the introduction of provenance standards could provide a pathway to restoring trust in what he calls the “information distribution infrastructure.”
“Misinformation can spread through social networks much faster than authentic information. This is a problem at a societal scale, not one that’s limited to a particular industry or discipline,” said Feng, lead author on the CSCW paper. “Being able to access a piece of media’s provenance, such as its prior edit history and sources, with just a click of a button could enable viewers to make more informed credibility judgments.”
Feng turned to the Coalition for Content Provenance and Authenticity (C2PA), which at the time was in the midst of developing an open-source technical standard for media authoring tools such as Adobe Photoshop to embed a distinct signature into an image’s metadata every time someone edits it. The goal was to provide a verifiable chain of provenance information — essentially, a detailed edit history — to viewers of online content.
But given the overall erosion of trust in online media, an important question remained.
“Even if we can reliably surface provenance information, we still didn’t know if or how that would impact users’ credibility judgements,” Feng noted. “This is an important question to answer before deploying such standards at scale.”
Seeking answers, Feng and Zhang teamed up with Nick Ritchie, user experience design principal at the BBC, and Pia Blumenthal and Andy Parsons, lead product designer and senior director, respectively, of Adobe’s Content Authenticity Initiative. The team ran a study involving 595 participants in the United States and United Kingdom in which they measured how access to provenance information altered users’ perceptions of accuracy and trust in visual content shared on social media.
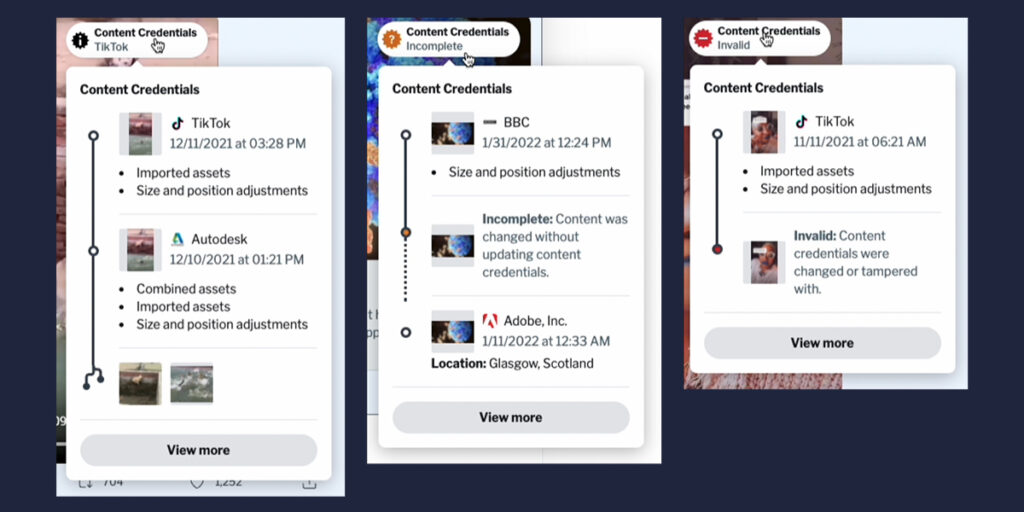
The team developed dual Twitter-esque social media feeds for the study: one regular feed, and one containing provenance information accessible through user interfaces built in accordance with the C2PA standard. The team relied on pre-existing images and videos sourced mainly from the Snopes “fauxtography” archives, representing a mix of truthful and deceptive content. Participants were asked to view the same series of images on the control feed followed by the experimental feed and rate the accuracy and trustworthiness of each piece of content on a 5-point scale. This enabled the researchers to gauge how each user’s perception of media credibility shifted once they had access to information about the content’s provenance.
And shift, it did.
“With access to provenance information, participants’ trust in deceptive media decreased and their trust in truthful media increased,” Feng reported. “Their ability to evaluate whether a claim associated with a particular piece of media was true or false also increased.”

Feng and his co-authors found that the use of provenance information comes with a couple of caveats. For example, if an image editor is incompatible with the C2PA standard, any changes to the image may render the chain of provenance information “incomplete,” which does not speak to the nature of the edit. In addition, if a malicious actor attempts to tamper with the metadata in which the provenance information is stored, the provenance is rendered as “invalid” to warn the user that suspicious activity may have occurred — whether or not the attempt was successful.
The team discovered that such disclosures had the effect of lowering trust in truthful as well as deceptive media, and caused participants to regard both as less accurate. The researchers were also surprised to learn that many users interpreted provenance information as prescribing a piece of media’s credibility — or lack thereof.
“Our goal with provenance is not necessarily to prescribe such judgements, but to provide a rich set of information that empowers users to make more informed judgments for themselves,” Zhang notes. “This is an important distinction to keep in mind when developing and presenting these tools to users.”
The team’s findings informed the eventual design of the production version of the C2PA standard, Content Credentials. But that’s not the only distinction that is reflected in the standard. When the study launched, generative AI had not yet come into the mainstream; now, AI images seem to be everywhere. This poses important questions about disclosure and attribution in content creation that, in Feng’s view, make provenance standards even more timely and relevant.
“As AI-generated content inevitably starts flooding the web, I think that provable transparency — being able to concretely verify media origins and history — will be crucial for deciphering fact from fiction,” he said.
Everything in moderation
When problematic posts cross the line from mendacious to mean, there are a variety of approaches for reducing users’ exposure to harmful content. These vary from platform–wide moderation systems to user-configured tools based on personal preference in response to the content posted by others. The emergence of the latter has sparked debate over the benefits and drawbacks of putting moderation decisions on individual users — attracting fans and foes alike.
In their recent CSCW paper, lead author Shagun Jhaver and his colleagues investigated this emerging paradigm, which they dubbed “personal content moderation,” from the perspective of the user.

“With more and more people calling for greater control over what they do, and do not, want to see on social media, personal moderation tools seem to be having a moment,” explained Jhaver, a former Allen School postdoc who is now a professor at Rutgers University where he leads the Social Computing Lab. “Given the growing popularity and utility of these tools, we wanted to explore how the design, moderation choices, and labor involved affected people’s attitudes and experiences.”
Personal moderation tools fall into one of two categories: account-based or content-based. The former includes tools like blocklists, which prevent posts by selected accounts from being displayed in a user’s feed. Jhaver, Zhang and their co-authors — Allen School postdoc Quan Ze Chen, Ph.D. student Ruotong Wang, and research intern Alice Qian Zhang, a student at the University of Minnesota who worked with the lab as part of the Computing Research Association’s Distributed Research Experiences for Undergraduates (DREU) program — were particularly interested in the latter. This category encompasses a range of tools enabling users to configure what appears in their feed based on the nature of the content itself.
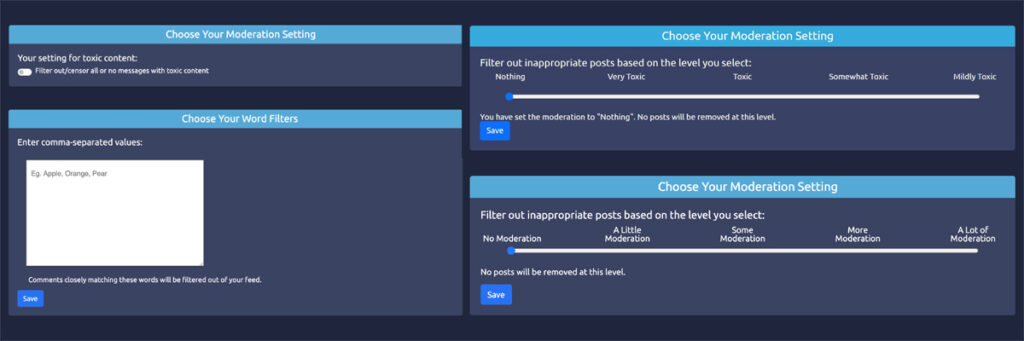
The researchers built a web application that simulates a social media feed, complete with sample content and a set of interactive controls that can be used to reconfigure what appears in the feed. The tools included a word filter, a binary toxicity toggle, an intensity slider ranging from “mildly” to “very” toxic, and a proportion slider for adjusting the ratio of benign to toxic comments. They then enlisted a diverse group of two dozen volunteers to interact with the configuration tools and share their insights via structured interviews.
The team discovered that participants felt the need to build a mental model of the moderation controls before they could comfortably engage with the settings, particularly in the absence of robust text explanations of what various moderation terms meant. Some users switched back and forth between their settings and news feed pages, using examples to tweak the configuration until they could verify it achieved their desired goals. The test interface supported this approach by enabling participants to configure only one of the four moderation interfaces at a time, which meant they could observe how their choices changed the feed.
This seemed particularly helpful when it came to slider-based controls that categorize content according to high-level definitions such as “hateful speech” or “sensitive content” — categories that users found too ambiguous. Context is also key. For example, participants noted that whether profanity or name-calling is offensive depends on the intent behind it; the mere presence of specific words doesn’t necessarily indicate harm. In addition, some participants were concerned that filtering too aggressively could curtail the visibility of content by members of minority communities reclaiming slurs as part of in-group conversations.
“Whether at the platform level or personal level, users crave more transparency around the criteria for moderation. And if that criteria is too rigid or doesn’t allow for context, even user-driven tools can cause frustration,” Zhang said. “There is also a tradeoff between greater agency over what appears in one’s feed and the effort expended on configuring the moderation settings. Our work surfaced some potential design directions, like the option to quickly configure predetermined sets of keywords or enable peer groups to co-create shared preferences — that could help strike a balance.”
Another tension Zhang and her team observed was between content moderation policies and users’ desire to preserve freedom of speech. Although users still believe there is a role for platforms in removing the most egregious posts, in other instances, personal moderation could provide an attractive alternative to a top-down, one-size-fits-all approach. In what Jhaver terms “freedom of configuration,” users choose the nature of the content they want to consume without curtailing other users’ self-expression or choices.
“These tools are controlled by the user, and their adoption affects only the content seen by that user,” Jhaver noted. “Our study participants drew a distinction between hiding a post from their individual feed and a platform removing a post for everyone, which could be considered censorship.”
While it may not chill free speech, personal moderation could meet with an icy reception from some users due to another social media phenomenon: the dreaded FOMO, or “fear of missing out.”
“Many of our participants worried more about missing important content than encountering toxic posts,” explained Jhaver. “Some participants were also hesitant to suppress inappropriate posts due to their desire to remain informed and take appropriate action in response.”
Whether it has to do with moderation or misinformation, the researchers are acutely aware of the societal implications of their work.
“As social computing researchers, we are the architects of our digital spaces,” Feng said. “The design decisions we make shape the ways with which people interact online, who they interact with, how they feel when doing so, and much more.”
For more on this topic, see the UW News Q&A featuring Zhang here.
Roger Van Scyoc contributed to this story.