The 1939 movie “The Wizard of Oz” opens in black and white. After a tornado sweeps up her Kansas home and drops it with a thud, Dorothy, the story’s protagonist, opens the front door, her dog Toto in tow. When she does, she’s greeted by a world of color.
“Toto, I have a feeling we’re not in Kansas anymore,” she says, eyes wide.
Allen School senior Matt Deitke is not from Kansas, nor has he been to the Land of Oz. Yet he experienced a similar revelation, minus the intervention from Hollywood or Mother Nature. When Deitke was in high school, he spent long hours using Adobe Photoshop to manually colorize images for personal projects. But the task was tedious and unavoidable, he said, a process to be endured rather than enjoyed.
That changed when he encountered a different kind of technical wizardry, one that opened up a new world of color. Via artificial intelligence, the process could be automated. A black-and-white image of a Monarch butterfly, for instance, underwent metamorphosis before his eyes, the orange of its wings bursting into arresting, vibrant life.
“I was completely amazed,” Deitke said. “Witnessing the impressive results, it felt like I was experiencing pure magic.”
Yet the laws behind this trick were governed by logic, not legerdemain. For the budding scientist, neither tornado nor Toto was needed. He wasn’t in “Kansas” anymore.
“This eye-opening experience led me to realize the impact computer vision would have on the field of computer graphics,” he said. “It soon became clear that these AI techniques would transform industries far beyond design.”
While Deitke doesn’t hail from the Sunflower State, he spent his youth in the Midwest, growing up in a suburb of Chicago. There he tinkered with computer graphics, interface design and visualization, completing projects for Ohio State University and the University of Cincinnati while still in high school. The possibilities of AI led him to the University of Washington, where he quickly channeled his curiosity into practice.
His first year brought several new experiences. As a freshman, he enrolled in a graduate computer vision course taught by Richard Szeliski, Steve Seitz and Harpreet Sawhney. At the time, Szeliski was revising his 2010 book “Computer Vision: Algorithms and Applications,” updating it to account for advances in deep learning. Deitke, not one shy to show his inquisitive side, wrote pages of comments to Szeliski on topics such as transformers and text-to-image generation. He asked probing questions, gave insightful suggestions and turned heads.
“At some point I said, ‘Would you be willing to write a section of the book?’” Szeliski said. “He agreed, and there’s a whole chapter on the more advanced topics of deep learning that he wrote.”
Deitke soon went on to author more impressive feats. Early in his time at the Allen School, he began working for The Allen Institute for AI (AI2), a global leader in advancing AI research, and became a full-time employee toward the end of his sophomore year.
“UW is an exceptional place to do AI research,” Deitke said. “Particularly now that AI progress requires a lot of engineering and computational power.”
One project Deitke recently completed, ProcTHOR, investigated scaling up the diversity of datasets used to train household robotic agents. He was lead author on the paper, which won an Outstanding Paper Award at the 2022 Neural Information Processing Systems (NeurIPS) Conference.
“Training robots in the real-world is difficult and time consuming,” Deitke said. “An emerging alternative is to train robots in photorealistic video-game simulators to make training much faster.”
Prior to ProcTHOR, artists had to manually design spaces such as simulated 3D houses. Deitke proposed a generative function to sample diverse and realistic house environments. It worked brilliantly.
“Training on the generated houses led to remarkably robust agents across several distributional shifts,” Deitke said. “We’ve still yet to hit a ceiling on how much further such a simple recipe can go.”
As it turns out, there’s no place like home. For Deitke, UW has been home for the past four years. With graduation nearing, he’s been weighing offers from several top doctoral programs, looking to continue his research and keep searching for that spark of “pure magic,” wherever it might be.
“The field of AI is beginning to change the world,” he said. “It is incredibly rewarding being able to work on the cutting-edge of research and pushing the frontier of what’s possible in science and technology.” Read more →
SIGCHI, the Association for Computing Machinery’s Special Interest Group on Computer-Human Interaction, has honored four researchers with ties to the University of Washington with 2023 SIGCHI Awards. Allen School alum Nicola (Nicki) Dell (Ph.D., ‘15), a leader in applying technologies to safeguard victims of technology-enabled intimate partner violence (IPV), received a Societal Impact Award, while Dhruv (DJ) Jain (Ph.D., ‘22), received an Outstanding Dissertation Award for his work on technologies to enhance sound awareness for people who are deaf or hard of hearing. In addition, Megan Hofmann, a visiting Ph.D. student at the UW who taught at the Allen School, and Kai Lukoff, a recent alum of the UW Department of Human-Centered Design & Engineering, also received Outstanding Dissertation Awards — a testament to the UW’s far-reaching impact on human-computer interaction (HCI) education and research through its Design Use Build (DUB) group.
Dell’s work seeks to understand, build and deploy sociotechnical systems that benefit those who are underserved both in the United States and in resource-constrained regions of the world. She draws from qualitative and quantitative methodologies and engages with people in real-world settings as well as in academia, industry, government and non-governmental organizations. At the Allen School, Dell collaborated with the late professor Gaetano Borriello and professors Richard Anderson and Linda Shapiro on research that combines HCI, Information and Communication Technologies for Development (ICTD) and computer vision and machine learning, such as mobile camera-based systems to advance data collection and disease diagnosis in low-resource settings.
“Nicki’s work has always looked at the impact of digital technology on marginalized populations,” noted Anderson. “As a graduate student, she pioneered mobile applications in global health in domains such as rapid diagnostics and digitized data collection. She has now established herself as a leading researcher understanding the way that digital technologies tie into very sensitive situations, such as intimate partner violence. I am thrilled that her work is recognized by SIGCHI as she is highly deserving of the award.”
Upon graduation from the UW, Dell joined the faculty of the Jacobs Technion-Cornell Institute at Cornell Tech and the Department of Information Science at Cornell University. There, her efforts to improve digital safety and security for those who have experienced IPV have resulted in greater support for individuals affected by IPV and impacted both policy and legal discourse. In 2018, Dell and her Cornell colleague Thomas Ristenpart co-founded the Clinic to End Tech Abuse (CETA), whose mission is to address targeted attacks emanating from technology abuse.
“Everyone should be free to use technology without fear of harm from abusive partners or others,” said Dell. “Survivors of abuse, stalking, or other mistreatment should have the support they need to keep themselves safe online and on their devices.”
Dell endeavors to understand both how survivors can stay safe and how abusers misuse technology. In 2017, she and Ristenpart undertook the initial research that would form the foundation on which they built CETA. Their paper, “A Stalker’s Paradise”: How Intimate Partner Abusers Exploit Technology, which won a Best Paper Award at SIGCHI 2018, described their findings from qualitative interviews conducted in New York City with those who had experienced technology enabled IPV. Their findings underscored how abusers threaten, harass, intimidate, monitor and harm victims by interacting with and compromising the victims accounts or devices through adversarial authentication. The authentication is often obtained as a result of the closeness between victim and abuser, but also through coercion, threats and violence. Dell’s subsequent work has explored care infrastructure for digital security in IPV to understand security support for those who have experienced technology enabled IPV as well as narrative justifications of intimate partner surveillance and tools and tactics of IPV through analyses of online forums.
Operating in New York City since 2018, CETA works directly with survivors of IPV to determine if someone is using technology to harm them and what they can do to stay safe. In parallel, CETA facilitates new research to understand how abusers can misuse technology, advocates for laws and policies that include better protections from technology abuse, and publishes resources for others who work to help survivors. At this time, their work has influenced legislation both in New York State and at the federal level. In December 2022, President Biden signed the Safe Connections Act into law. This legislation supports survivors’ requests to have themselves or those in their care removed from shared phone plans while retaining their phone numbers for uninterrupted connectivity. Other proposed legislation would require cellular providers to create strong privacy protection with regard to information about abuse, to eliminate difficult or trauma producing requirements for survivors, and to train employees about survivors’ rights.
Dhruv Jain
“[Dell’s] work is exemplary in many regards, representing an unusually ‘full stack’ model of intervention and social impact,” wrote Neha Kumar, president of SIGCHI and a professor at the Georgia Institute of Technology, in the award announcement. “She has been the driving force in putting tech-related IPV abuses on the radar of companies, government, and HCI as a field; has offered direct and meaningful support to survivors; and has produced real-world changes that have begun to combat this pervasive and insidious problem.”
Dell is one of three recipients of this year’s SIGCHI Societal Impact Awards, including Shaowen Bardzell, a professor at Pennsylvania State University, and Munmun De Choudhury, a professor at the Georgia Institute of Technology.
Jain takes a user centered approach to better understand sound awareness, sensing and technology preferences and needs of those who are DHH. After first evaluating the needs and preferences of those who are DHH, Jain employed an iterative approach in both the lab and the field to design, build and evaluate new systems that could support real-time sound recognition — informed in part by his own experiences as a DHH individual.
“Dhruv’s dissertation exemplifies the use of end-to-end human-centered research to define and advance methods and tools for real-time sound recognition,” Froehlich expressed. “Fundamentally, his work advances our understanding of DHH people’s needs around sound recognition and provides technical solutions to support those needs.”
Jain’s research led him to develop several such systems, including HoloSound, an augmented reality (AR) system that allows DHH individuals to receive a classification and visualization of sound along with speech transcription. Another project, HomeSound, explored how DHH people relate to sounds in the home, how they solicit and relate to feedback from home awareness systems, and what concerns arise with the use of these systems. Jain also developed a smartwatch app called SoundWatch that alerts people who are DHH to sounds in their environment.
Currently a professor at the University of Michigan, Jain builds on the research agenda that he developed during his Ph.D. work. He directs the Accessibility Lab, where he and his collaborators take a user-centered approach with the goal to make sound accessible to all people in all settings. Before the SIGCHI award, Jain received the Allen School’s William Chan Memorial Dissertation Award, which honors graduate dissertations of exceptional merit and is named in memory of the late graduate student William Chan.
Megan Hofmann (left) and Kai Lukoff
For her award-winning dissertation, “Optimizing Medical Making,” Hofmann worked with professor Jennifer Mankoff, who joined the Allen School faculty from CMU, on an interdisciplinary approach to the application of digital fabrication in health care. Combining programming languages, systems and ethnographic methodology, Hofmann introduces new ways that digital fabrication can be a tool to design assistive and medical devices informed by the domain expertise of people with disabilities and the medical knowledge of clinicians. This groundbreaking work has already had real-world influence in the application of clinical review processes to the production of personal protective equipment (PPE) during the COVID-19 pandemic.
The third UW-affiliated researcher to earn an Outstanding Dissertation Award, Lukoff explores the concept of user agency in a world where application design patterns strive to capture user attention, often without regard for the user’s well-being. His dissertation, “Designing to Support Sense of Agency for Time Spent on Digital Interfaces,” co-advised by HCDE professor and Allen School adjunct faculty member Sean Munson and Information School professor and Allen School adjunct faculty member Alexis Hiniker, goes beyond the concept of “screen time” to offer insights into how users’ experiences with digital interfaces can be meaningful or meaningless depending on the context and goals. Lukoff built a mobile app, SwitchTube, to investigate design features that allowed users a greater sense of agency when consuming online video content. He continues to build upon this line of inquiry at Santa Clara University, where he is a professor and director of the Human-Computer Interaction Lab.
Congratulations to this year’s SIGCHI award recipients! Read more →
Buzek is a junior studying computer science and mathematics who counts Allen School professor Paul Beame among his mentors. His research focuses on number theory and cryptography, and he and his collaborators have investigated finding twin smooth integers — very large consecutive integers with prime factors that are as small as possible. His team recently completed a project that uncovered new, more efficient algorithms to find these integer pairs.
An avid hiker, Buzek remembers trying to factor large numbers in his head while trekking through nature as a child. He would make a game of guessing factors without having to try a lot of primes.
For Buzek, work and play have coalesced, and the game never ended.
“I was fascinated by the mysterious structure present in such a seemingly simple object — integers and multiplication,” he said. “This problem of factoring has stayed with me throughout my studies.”
This year, Buzek is studying abroad at the University of Heidelberg and ETH Zürich. He plans to pursue a doctorate in cryptography.
“This recognition is great motivation for me to further pursue my research, and increases my enthusiasm for the role of cryptography in today’s world,” Buzek said. “I would like to thank all of my mentors, especially my recommenders Michael Naehrig, Stefan Steinerberger and Paul Beame for their support and the motivation they have given me to pursue my interests.”
Chandra is a senior majoring in computer science and minoring in global health. As part of her work with professor Sara Mostafavi in the Allen School’s Computational Biology Group, she uses deep learning to study regulatory genetics in immune cells. She has also conducted chronic pain research at Seattle Children’s Hospital with Dr. Jennifer Rabbitts and geometric combinatorics research with professor Rekha Thomas in the UW Department of Mathematics.
As a teenager, Chandra started to have immune-related health problems. Her own experiences led her to pursue biomedical research at UW and then at Seattle Children’s Hospital.
“When trying to understand my own health, I found that the immune system’s functions and dysfunctions are poorly understood,” she said. “I saw research as a way to help prevent and cure diseases that I had a personal connection with.”
But while at UW, her academic interests broadened. She was exposed to computer science for the first time, she said, and the experience kindled her passion for algorithmic approaches to problem solving. She switched her major to computer science, seeing a path where her fields of study could overlap.
“I became interested in machine learning and deep learning because I saw what a powerful potential impact it has for improving our understanding of human health,” she said. “My computational biology research in the Mostafavi Lab has allowed me to use my interest in computer science to work toward understanding the diseases that I care deeply about.”
Her research is ongoing. The goal, she said, is to find a deep learning model that provides a clearer understanding of immune diseases and the genetic mechanisms behind them.
“Gaining this type of understanding of how immunological diseases work will also help researchers develop preventative treatments,” she said, “so the disease never develops in the first place.”
Last year, Chandra was named to the 2022 class of the Husky 100. She plans to pursue a doctorate in computer science, focusing on the intersection of machine learning, computational biology and algorithms research.
“It makes me feel very proud to have my work as an undergraduate researcher acknowledged by this award,” Chandra said. “I have been fortunate to find many exceptional mentors at UW who have supported my research journey. I want to thank Jennifer Rabbitts, Rekha Thomas, Alexander Sasse and Sara Mostafavi for dedicating their time and energy to helping me grow as a researcher.”
Including Chandra and Buzek, a total of five UW students were named Goldwater Scholars for 2023. The other honorees were Abigail Burtner, a junior majoring in biochemistry and minoring in data science and chemistry; Meg Takezawa, a junior majoring in biochemistry; and Peter Yu, a junior majoring in civil and environmental engineering. They were selected from a pool of more than 5,000 students from across the U.S.
The team competed at the Tech For Change Civic Tech Hackathon hosted by Boston University, winning the election turnout track. Photo by Impact++
In February, University of Washington student group Impact++ won one of the tracks at the Tech For Change Civic Tech (TFC) Hackathon held at Boston University. The hackathon tasked student teams with building creative solutions in the interest of changing public policy. This year’s competition included three tracks: education, election turnout and government policy rooted in social welfare.
It was the first time Impact++, which focuses on projects combining computer science and social good, has sent a team to the TFC Hackathon hosted by Boston University’s Spark program. The team consisted of: Vrishab Sathish Kumar, a senior studying computer science; Aditi Joshi, a junior majoring in computer science and minoring in environmental studies; Samuel Levy, a senior majoring in computer science and minoring in law societies and justice; and Ian Mahoney, a senior majoring in computer science and minoring in history. Masia Wisdom, a sophomore studying computer engineering at Howard University, also joined the UW team during the first day after meeting the group at the event.
“The hackathon helped me understand that even without formal internship experience or past in-person hackathon experience, our training through the Allen School and Impact++ projects were truly translational to other, perhaps different settings,” Sathish Kumar said. “It was a full-circle experience to see a project come together through teamwork.”
The team’s project tackled the election turnout challenge. Called Vote Real, it provided a gamified platform in which users act as a city council member. Through the platform they could better understand bills being voted on besides the intricacies of the policy-making process. Then users could see how their own city council members voted.
“Over time, this ‘closeness’ metric of how a user voted, opposed to how council members voted, will keep them in the loop,” Joshi said. “Instead of voting for representatives once a year and forgetting about it for the rest, the goal is to keep our leaders accountable.”
The team based its idea on BeReal, a social app gaining popularity among 18 to 24-year-olds. After multiple rounds of brainstorming, the group decided to focus on improving voter turnout in local elections, which historically have lower participation among younger voters.
The team included Howard University sophomore Masia Wisdom (left) and UW Impact++ undergraduates Vrishab Sathish Kumar, Samuel Levy, Ian Mahoney and Aditi Joshi. Photo by Impact++
“We recognized a gap here and wanted to build something to help around this issue,” Sathish Kumar said. “Since we are in the same shoes as our target audience, we thought about what mattered to us, what motivated us and the mediums that we thought were most effective in doing so.”
Since its formation in 2018, Impact++ has provided opportunities for students to gain hands-on experience and build connections with industry mentors through social-good projects. The student-run organization runs five to six annual projects, Sathish Kumar said, with support from mentors from local tech companies and startups.
Experiences like the TFC Hackathon, for instance, can broaden perspectives. For several of the team members, participating helped them think more deeply about technology’s role in society.
“I had not really thought too much about the topic of creating social and policy change through tech and computing before the TFC Hackathon,” Mahoney said. “Through the hackathon and our project in particular, I realized there are spaces in which technology can really have an impact in creating these changes.”
There was also time for fun. Less so for sleep. Between making presentation slides and games of Jeopardy and Kahoot, the hours flew by in a whirlwind of creating and camaraderie.
“In the morning, we were so delirious after staying up most of the night that we spent a solid 30 minutes crying with laughter,” Levy said. “None of us could figure out why.”
After more than 30 hours of hacking, it was the only answer that eluded the team. Read more →
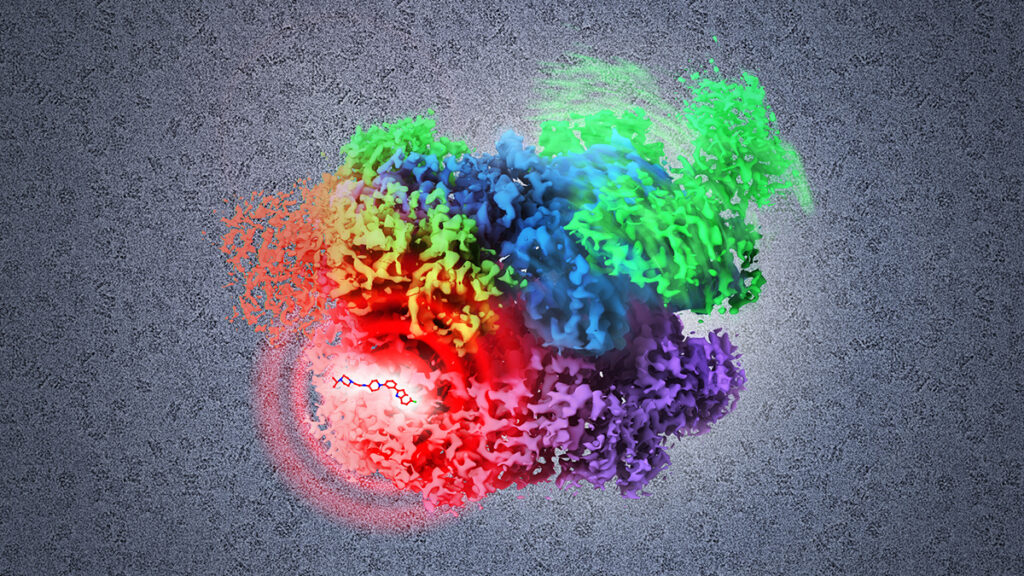
A visualization of p97, an enzyme that plays a crucial role in regulating proteins in cancer cells, inhibited from completing its normal reaction cycle by a potential small molecule drug. With BioTranslator, the first multilingual translation framework for biomedical research, scientists will be able to search potential drug targets like p97 and other non-text biological data using free-form text descriptions. National Cancer Institute, National Institutes of Health
When the novel coronavirus SARS-Cov-2 began sweeping across the globe, scientists raced to figure out how the virus infected human cells so they could halt the spread.
What if scientist had been able to simply type a description of the virus and its spike protein into a search bar, and received information on the angiotensin-converting enzyme 2 — colloquially known as the ACE2 receptor, through which the virus infects human cells — in return? And what if, in addition to identifying the mechanism of infection for similar proteins, this same search also returned potential drug candidates that are known to inhibit their ability to bind to the ACE2 receptor?
Biomedical research has yielded troves of data on protein function, cell types, gene expression and drug formulas that hold tremendous promise for assisting scientists in responding to novel diseases as well as fighting old foes such as Alzheimer’s, cancer and Parkinson’s. Historically, their ability to explore these massive datasets has been hampered by an outmoded model that relied on painstakingly annotated data, unique to each dataset, that precludes more open-ended exploration.
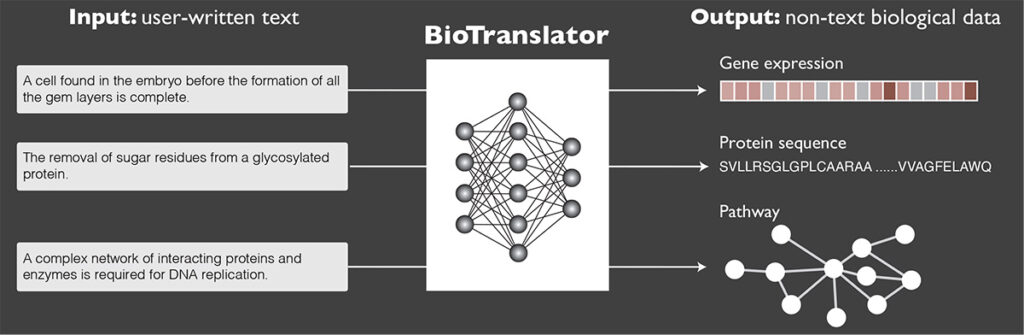
But that may be about to change. In a recent paper published in Nature Communications, Allen School researchers and their collaborators at Microsoft and Stanford University unveiled BioTranslator, the first multilingual translation framework for biomedical research. BioTranslator — a portmanteau of “biological” and “translator” — is a state-of-the-art, zero-shot classification tool for retrieving non-text biological data using free-form text descriptions.
Hanwen Xu (left) and Addie Woicik
“BioTranslator serves as a bridge connecting the various datasets and the biological modalities they contain together,” explained lead author Hanwen Xu, a Ph.D. student in the Allen School. “If you think about how people who speak different languages communicate, they need to translate to a common language to talk to each other. We borrowed this idea to create our model that can ‘talk’ to different biological data and translate them into a common language — in this case, text.”
The ability to perform text-based search across multiple biological databases breaks from conventional approaches that rely on controlled vocabularies (CVs). As the name implies, CVs come with some constraints. Once the original dataset is created via the painstaking process of manual or automatic annotation according to a predefined set of terms, it is difficult to extend them to the analysis of new findings; meanwhile, the creation of new CVs is time consuming and requires extensive domain knowledge to compose the data descriptions.
BioTranslator frees scientists from this rigidity by enabling them to search and retrieve biological data with the ease of free-form text. Allen School professor Sheng Wang, senior author of the paper, likens the shift to when the act of finding information online progressed from combing through predefined directories to being able to enter a search term into open-ended search engines like Google and Bing.
Sheng Wang
“The old Yahoo! directories relied on these hierarchical categories like ‘education,’ ‘health,’ ‘entertainment’ and so on. That meant that If I wanted to find something online 20 years ago, I couldn’t just enter search terms for anything I wanted; I had to know where to look,” said Wang. “Google changed that by introducing the concept of an intermediate layer that enables me to enter free text in its search bar and retrieve any website that matches my text. BioTranslator acts as that intermediate layer, but instead of websites, it retrieves biological data.”
Wang and Xu previously explored text-based search of biological data by developing ProTranslator, a bilingual framework for translating text to protein function. While ProTranslator is limited to proteins, BioTranslator is domain-agnostic, meaning it can pull from multiple modalities in response to a text-based input — and, as with the switch from old-school directories to modern search engines, the person querying the data no longer has to know where to look.
BioTranslator does not merely perform similarity search on existing CVs using text-based semantics; instead, it translates the user-generated text description into a biological data instance, such as a protein sequence, and then searches for similar instances across biological datasets. The framework is based on large-scale pretrained language models that have been fine-tuned using biomedical ontologies from a variety of related domains. Unlike other language models that are having a moment — ChatGPT comes to mind — BioTranslator isn’t limited to searching text but rather can pull from various data structures, including sequences, vectors and graphs. And because it’s bidirectional, BioTranslator not only can take text as input, but also generate text as output.
“Once BioTranslator converts the biological data to text, people can then plug that description into ChatGPT or a general search engine to find more information on the topic,” Xu noted.
BioTranslator functions as an intermediate layer between written text descriptions and biological data. The framework, which is based on large-scale pretrained language models that have been refined using biological ontologies from a variety of domains, translates user-generated text into a non-text biological data instance — for example, a protein sequence — and searches for similar instances across multiple biological datasets. Nature Communications
Xu and his colleagues developed BioTranslator using an unsupervised learning approach. Part of what makes BioTranslator unique is its ability to make predictions across multiple biological modalities without the benefit of paired data.
“We assessed BioTranslator’s performance on a selection of prediction tasks, spanning drug-target interaction, phenotype-gene association and phenotype-pathway association,” explained co-author and Allen School Ph.D. student Addie Woicik. “BioTranslator was able to predict the target gene for a drug using only the biological features of the drugs and phenotypes — no corresponding text descriptions — and without access to paired data between two of the non-text modalities. This sets it apart from supervised approaches like multiclass classification and logistic regression, which require paired data in training.”
BioTranslator outperformed both of those approaches in two out of the four tasks, and was better than the supervised approach that doesn’t use class features in the remaining two. In the team’s experiments, BioTranslator also successfully classified novel cell types and identified marker genes that were omitted from the training data. This indicates that BioTranslator can not only draw information from new or expanded datasets — no additional annotation or training required — but also contribute to the expansion of those datasets.
Hoifung Poon (left) and Dr. Russ Altman
“The number of potential text and biological data pairings is approaching one million and counting,” Wang said. “BioTranslator has the potential to enhance scientists’ ability to respond quickly to the next novel virus, pinpoint the genetic markers for diseases, and identify new drug candidates for treating those diseases.”
Other co-authors on the paper are Allen School alum Hoifung Poon (Ph.D., ‘11), general manager at Microsoft Health Futures, and Dr. Russ Altman, the Kenneth Fong Professor of Bioengineering, Genetics, Medicine and Biomedical Data Science, with a courtesy appointment in Computer Science, at Stanford University. Next steps for the team include expanding the model beyond expertly written descriptions to accommodate more plain language and noisy text.
An aerial view of São Paulo, Brazil, one of five cities in the Americas that have partnered with the Taskar Center and G3ict on the award-winning “AI for Inclusive Urban Sidewalks” project supported by AI for Accessibility and Bing Maps at Microsoft. As part of the initiative, São Paulo officials aim to rehabilitate or reclassify more than 1.5 million square meters of sidewalk in key areas of the city to improve walkability and safety. Photo by Gabriel Ramos on Unsplash
To say Anat Caspi’s mission is pedestrian in nature would be accurate to some degree. And yet, when looked at more closely, one realizes it’s anything but.
In 2015, the Allen School scientist was thinking about how to build a trip planner that everyone could use, similar to Google Maps but different in striking ways. Current tools didn’t account for various types of pedestrians and the terrain they confronted on a daily basis. What if there were barriers blocking the sidewalk? A steep incline listing to and fro? Stairs but no ramp?
“Map applications make very specific assumptions about the fact that if there’s a road built there, you can walk it,” Caspi said. “They’ll just give you a time estimate that’s a little bit lower than the car and call it done.”
But Caspi was just beginning. Artificial intelligence could only do so much. These tools were powerful, sure, but treated people as “slowly moving cars.” They lacked perspective, something with resolve and purpose, a cleareyed intent. Something, perhaps, more human.
Nearly a decade later, Caspi’s quest continues. As the director of the Taskar Center for Accessible Technology (TCAT), and lead PI of the Transportation Data Equity Initiative, she spearheads an initiative that seeks to make cities smarter and safer for everyone. About one out of every six people worldwide experiences a significant disability, according to the World Health Organization, and many encounter spaces designed without them in mind.
“Which is unacceptable given that we now have the ability to convey real information,” she said. “It’s just about the political will to make these changes.”
TCAT has filled in those gaps and more. Several of its projects have gone from print to pavement to public initiative. For instance, AccessMap, an app providing accessible pedestrian route information customized to the user, garnered a large yet unanticipated fan base shortly after its release in 2017: parents pushing strollers.
Though originally designed for those with disabilities in mind, AccessMap quickly gained a following with groups whose transportation needs ran the gamut.
“I’m focused on accessibility,” Caspi said. “But as soon as we started putting this data out, it was clear that there were many other stakeholders who were interested.”
Besides those with tykes in tow, first responders also expressed their interest after seeing the app’s potential for helping negotiate tricky areas surrounding search and rescue — or moving a stretcher to a patient. City planners saw the app’s utility for helping coordinate construction, assessing walkability and transportation planning efforts.
The tactile graphic representation of the OpenSidewalks data specification. The tactile map presents an alternative approach to understanding the pedestrian experience, where roads are demoted, pedestrian spaces such as parks and pedestrian paths are elevated on the map, and pedestrian amenities and landmarks are shown for a particular travel purpose. Photo by TCAT
AccessMap was the first act of OpenSidewalks, TCAT’s team project that creates an ecosystem of tools including machine learning and crowdsourcing to map pedestrian pathways better, and in a standardized, consistent manner. OpenSidewalks started as a Data Science for Social Good eScience project. Now, the venture has evolved into a global effort, one with key partners such as USDOT, Microsoft and the Global Initiative for Inclusive Information and Communication Technologies (G3ict). The USDOT funding is part of a larger initiative to create public infrastructure to support multimodal accessibility-first transportation data. Sponsors for the current ongoing project include the U.S. Department of Transportation ITS4US Deployment Program. Learn more about that project here.
AI for Accessibility and Bing Maps at Microsoft also provided financial and infrastructure support for the project.
G3ict, a nonprofit with roots in the United Nations, partnered with TCAT on the shared mission of improving accessibility in cities from a transportation and mobility perspective. Prior to the partnership, G3ict had focused more on digital accessibility — procuring software to enable residents to pay utility bills online, for example.
“This was really their first time looking at the physical environment from the accessibility perspective,” Caspi said. “For us, most of our prior experience had been in the U.S., so the tools we had created before both for using model predictions and for collecting the data were U.S. specific. This really forced us to expand our thinking.”
Together, the organizations could reach further. G3ict brought in entities from municipalities around the world, providing greater access and scope to the project. TCAT, meanwhile, leveraged its expertise in mapping and data collection to take accessibility from the screen to the streets.
“We are super happy about the partnership,” Caspi said. “Without people on the ground, you really don’t have that kind of reach typically.”
In November, TCAT and G3ict won the Smart City Expo World Congress Living & Inclusion Award for their project, “AI for Inclusive Urban Sidewalks.” The project seeks to build an open AI network dedicated to improving pedestrian accessibility around the world.
TCAT has previously collaborated with 11 cities across the U.S. and is currently partnering with 10 other cities across the Americas, including São Paulo, Los Angeles, Quito, Gran Valparaiso and Santiago, with more planned for the future.
Felipe Tapia, a project participant in Latin America, rides trails on an adapted bicycle and collects sidewalk and path data in his city, Santiago in Chile. Photo by Felipe Tapia
While working with the cities, Caspi has found that each has its own personality and set of challenges specific to its location. Quito, for instance, has been focused on greenery and access to nature. The team in Los Angeles has emphasized studying building footprints and how structures interact with sidewalk environments. Meanwhile, in São Paulo, officials are prioritizing more than 1.5 million square meters of sidewalk rehabilitation and reclassification, with the hope of improving safety and walkability in key areas across the city.
“We found as we built the data more, we could reach further in terms of whom this data was relevant for and how they were using it,” Caspi said. “Through efforts focused on eco-friendly cities, transportation and people being able to reach transit services, you’re supporting sustainability within those communities.”
Caspi added that the collaboration, both within TCAT and without, has been essential and has also surprised her in how it has grown and changed shape over the years. Whether working with transportation officers in local governments or on the ground with students collecting the data, she’s seen firsthand how these efforts can build upon themselves into something greater.
For instance, Ricky Zhang, a Ph.D. student in Electrical & Computer Engineering who worked on the team, uses computer vision models to take datasets of aerial satellite images, street network image tiles and sidewalk annotations to infer the layout of pedestrian routes in the transportation system. His work was crucial to the project’s success, Caspi said.
“We hope to provide a data foundation for innovations in urban accessibility,” Zhang said. “The data can be used for accessibility assessment and pedestrian path network graph comparison at various scales.”
Eric Yeh developed the mobile version of the AccessMap web app while working with TCAT as an Allen School undergraduate. He saw the app’s potential for good, how routes in life or the everyday could branch out for the better.
“I originally joined TCAT because I was new to computer science,” said Yeh, now a master’s student studying computer science at the Allen School. “I wanted to gain programming experience while contributing to a project that would be meaningful to the community.”
The app lends itself to collaboration. Users can report sidewalk segments that are incorrectly labeled or are inaccessible, Yeh said, allowing for evolution and up-to-date accuracy. The team hopes to funnel these reports into a pipeline that automates the process.
It’s all part of a larger plan. Caspi outlined current work, including taking OpenSidewalks to a national data specification like GTFS to provide a consistent graph representation of pedestrians’ travel environments; democratization of data collection; improved tooling for data producers; and API’s that facilitate consuming the data at scale, all while limiting subjective assessments of what is considered accessible. At the same time, the Taskar Center is also pursuing non-technical tools like toolkits and workshop supports for transportation planners to discuss disability justice in their organizations and utilize community-based participatory design in trip planning and accessibility-first data stewardship. The center is also working with advocacy groups and communities to assess their accessibility and hold officials to account through a clear understanding of what the infrastructure does and does not support regarding accessibility.
For Caspi, it’s been a humbling experience to see how far the project has come, and how much work there is left to do. She sees the Taskar Center as part of a greater effort in building a sense of community, wherever one might be in the world.
“These kinds of projects can bring people together to have a better mutual understanding,” she said. “What does it take to run a city? It’s hard, right? So much from the municipal side is trying to understand storytelling and the lived experience of people through the city. Efforts like these can soften the edges around where cities meet their people. To me, that’s been really instructive.”
GlucoScreen would enable people to self-screen for prediabetes using a modified version of a commercially available test strip with any smartphone — no separate glucometer required. Leveraging the phone’s built-in capacitive touch sensing capabilities, GlucoScreen transmits test data from the strip to the phone via a series of simulated taps on the screen. The app applies machine learning to analyze the data and calculate a blood glucose reading. Raymond C. Smith/University of Washington
According to the U.S. Centers for Disease Control, one out of every three adults in the United States have prediabetes, a condition marked by elevated blood sugar levels that could lead to the development of type 2 diabetes. The good news is that, if detected early, prediabetes can be reversed through lifestyle changes such as improved diet and exercise. The bad news? Eight out of 10 Americans with prediabetes don’t know that they have it, putting them at increased risk of developing diabetes as well as disease complications that include heart disease, kidney failure and vision loss.
Current screening methods typically involve a visit to a health care facility for laboratory testing and/or the use of a portable glucometer for at-home testing, meaning access and cost may be barriers to more widespread screening. But researchers at the University of Washington’s Paul G. Allen School of Computer Science & Engineering and UW Medicine may have found the sweet spot when it comes to increasing early detection of prediabetes. They developed GlucoScreen, a new system that leverages the capacitive touch sensing capabilities of any smartphone to measure blood glucose levels without the need for a separate reader. Their approach will make glucose testing less costly and more accessible — particularly for one-time screening of a large population.
The team describes GlucoScreen in a new paper published in the latest issue of the Proceedings of the Association for Computing Machinery on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT).
“In conventional screening, a person applies a drop of blood to a test strip, where the blood reacts chemically with the enzymes on the strip. A glucometer is used to analyze that reaction and deliver a blood glucose reading,” explained lead author Anandghan Waghmare, a Ph.D. student in the Allen School’s UbiComp Lab. “We took the same test strip and added inexpensive circuitry that communicates data generated by that reaction to any smartphone through simulated tapping on the screen. GlucoScreen then processes the data and displays the result right on the phone, alerting the person if they are at risk so they know to follow up with their physician.”
The GlucoScreen test strip samples the electrochemical reaction induced by the mixing of blood and enzymes as an amplitude along a curve at a rate of five times per second. The strip transmits this curve data to the phone encoded in a series of touches at variable speeds using a technique called pulse width modulation. “Pulse width” refers to the distance between peaks in the signal — in this case, the length between taps. Each pulse width represents a value along the curve; the greater the distance between taps for a particular value, the higher the amplitude associated with the electrochemical reaction on the strip.
The GlucoScreen app walks the user through each step of the testing process, which is similar to a conventional glucometer-based test. Tiny photodiodes on the GlucoScreen test strip enable it to draw the power it needs to function entirely from the phone’s flash. (Note: The blood in the photo is not real.) Raymond C. Smith/University of Washington
“You communicate with your phone by tapping the screen with your finger,” said Waghmare. “That’s basically what the strip is doing, only instead of a single tap to produce a single action, it’s doing multiple taps at varying speeds. It’s comparable to how Morse code transmits information through tapping patterns.”
The advantage of this technique is that it does not require complicated electronic components, which minimizes the cost to manufacture the strip and the power required for it to operate compared to more conventional communication methods like Bluetooth and WiFi. All of the data processing and computation occurs on the phone, which simplifies the strip and further reduces the cost.
“The test strip doesn’t require batteries or a USB connection,” noted co-author Farshid Salemi Parizi, a former Ph.D. student in the UW Department of Electrical & Computer Engineering who is now a senior machine learning engineer at OctoML. “Instead, we incorporated photodiodes into our design so that the strip can draw what little power it needs for operation from the phone’s flash.”
The flash is automatically engaged by the GlucoScreen app, which walks the user through each step of the testing process. First, a user affixes each end of the test strip to the front and back of the phone as directed. Next, they prick their finger with a lancet, as they would in a conventional test, and apply a drop of blood to the biosensor attached to the test strip. After the data is transmitted from the strip to the phone, the app applies machine learning to analyze the data and calculate a blood glucose reading.
That stage of the process is similar to that performed on a commercial glucometer. What sets GlucoScreen apart, in addition to its novel touch technique, is its universality.
“Because we use the built-in capacitive touch screen that’s present in every smartphone, our solution can be easily adapted for widespread use. Additionally, our approach does not require low-level access to the capacitive touch data, so you don’t have to access the operating system to make GlucoScreen work.” explained co-author Jason Hoffman, a Ph.D. student in the Allen School. “We’ve designed it to be ‘plug and play.’ You don’t need to root the phone — in fact, you don’t need to do anything with the phone, other than install the app. Whatever model you have, it will work off the shelf.”
After processing the data from the test strip, GlucoScreen displays the calculated blood glucose reading on the phone. Raymond C. Smith/University of Washington
Hoffman and his colleagues evaluated their approach using a combination of in vitro and clinical testing. Due to the COVID-19 pandemic, they had to delay the latter until 2021 when, on a trip home to India, Waghmare connected with Dr. Shailesh Pitale at Dew Medicare and Trinity Hospital. Upon learning about the UW project, Dr. Pitale agreed to facilitate a clinical study involving 75 consenting patients who were already scheduled to have blood drawn for a laboratory blood glucose test. Using that laboratory test as the ground truth, Waghmare and the team evaluated GlucoScreen’s performance against that of a conventional strip and glucometer.
While the researchers stress that additional testing is needed, their early results suggest GlucoScreen’s accuracy is comparable to that of glucometer testing. Importantly, the system was shown to be accurate at the crucial threshold between a normal blood glucose level at or below 99 mg/dL, and prediabetes, defined as a blood glucose level between 100 and 125 mg/dL. Given the scarcity of training data they had to work with for the clinical testing model, the researchers posit that GlucoScreen’s performance will improve with more inputs.
According to co-author Dr. Matthew Thompson, given how common prediabetes as well as diabetes are globally, this type of technology has the potential to change clinical care.
“One of the barriers I see in my clinical practice is that many patients can’t afford to test themselves, as glucometers and their test strips are too expensive. And, it’s usually the people who most need their glucose tested who face the biggest barriers,” said Thompson, a family physician and professor in the UW Department of Family Medicine and Department of Global Health. “Given how many of my patients use smartphones now, a system like GlucoScreen could really transform our ability to screen and monitor people with prediabetes and even diabetes.”
GlucoScreen is presently a research prototype; additional user-focused and clinical studies, along with alterations to how test strips are manufactured and packaged, would be required before the system could be made widely available. According to senior author Shwetak Patel, the Washington Research Foundation Entrepreneurship Endowed Professor in Computer Science & Engineering and Electrical & Computer Engineering at the UW, the project demonstrates how we have only begun to tap into the potential of smartphones as a health screening tool.
“Now that we’ve shown we can build electrochemical assays that can work with a smartphone instead of a dedicated reader, you can imagine extending this approach to expand screening for other conditions,” Patel said.
Yuntao Wang, a research professor at Tsinghua University and former visiting professor at the Allen School, is also a co-author of the paper. This research was funded in part by the Bill & Melinda Gates Foundation.
A little more than two decades ago, University of Washington professor Georg Seelig began planting the seeds of a career in theoretical physics, seeking elegant solutions to the mysteries of the natural world. Last month, Seelig, a faculty member in the Allen School and Department of Electrical & Computer Engineering, was hailed as the “DNA Computer Scientist of the Year” by the International Society for Nanoscale Science, Computation and Engineering (ISNSCE), who named him the winner of the 2023 Rozenberg Tulip Award in recognition of his leadership and original contributions that have advanced the field of DNA computing.
“It’s wonderful to get this recognition from my community,” Seelig said. “The field has grown quite a bit since the beginning but remains very collaborative and collegial.”
Seelig’s work with DNA strand displacement, scalable DNA data storage and retrieval, and technologies for single-cell sequencing and analysis of gene regulation has helped push the frontiers of molecular programming. For instance, he pioneered adapting strand displacement technology to living cells. Prior to his work, inputs to the circuits were synthesized chemically and not produced inside a cellular environment.
“This brings up a whole range of different challenges because the interior of cells is an infinitely more complex environment than a test tube with a bit of salt water,” Seelig said. “Cells are full of proteins that destroy foreign DNA and other molecules that sequester it in different subcellular compartments.”
Now a leader in the field, Seelig said a turning point for him came early on in his academic journey. Before his internship at Bell Laboratories, he had trained as a theoretical physicist. He didn’t think of himself as a practitioner.
But his perspective changed after meeting Bernard Yurke, a physicist at Bell who was building a synthetic molecular motor that could revolutionize the field. Dubbed “molecular tweezers” for its pincer-like mimicry, the motor could be switched between an open and a closed configuration by adding two more synthetic DNA strands.
The work struck Seelig with its simplicity — with just a few tweaks, scientists could, quite literally, bend the building blocks of life to their liking.
“The idea seemed both almost trivial,” he said, “and incredibly brilliant.”
That brilliance has followed him throughout his career. Since joining the UW faculty of the Allen School and the UW Department of Electrical & Computer Engineering in 2008, Seelig has continued to make the magical actual and sleight of hand scientific.
Seelig remembers how he grew after his experience at Bell Labs. After completing his doctorate at the University of Geneva, the Swiss scientist dove further into experimental work as a postdoc at the California Institute of Technology. There, he and Yurke joined MacArthur Fellow Erik Winfree’s lab, collaborating with some of the brightest minds in molecular engineering. Like Yurke before him, Winfree, a leading researcher in the field, mentored Seelig and fostered his potential.
“It wasn’t long after he joined my lab that I began to think of him as a rock star of science,” Winfree said. “Sometimes more Serge Gainsberg, sometimes more Richard Ashcroft, sometimes more John Prine, but always undeniably Georg Seelig.”
Together with David Soloveichik, a graduate student in the lab at the time, and David Yu Zhang, then an undergraduate, Seelig invented DNA strand displacement circuits, which allowed scientists to control the forces behind synthetic DNA devices. Being able to program the foundations of existence, to maneuver its scaffolding to one’s will, brought with it new questions besides tantalizing possibilities.
What if these reactions could target cancer cells via smart therapeutics? Could the reactions be sped up or slowed down? In DNA’s twists and turns, can the plot of a human life change for the better?
“It was a remarkably creative interaction, blending motivation from biophysics, biotechnology, theoretical computer science, the origin of life, electrical engineering, chemistry and molecular biology, and it resulted in several papers that had an enormous impact on the field,” Winfree said. “Georg’s vision, leadership, perseverance and exquisite experimental skills made the magic real and undeniable.”
The challenge of making “magic” feeds his curiosity, which Winfree likened to an artist’s muse. As head of the Seelig Lab for Synthetic Biology and a member of the Molecular Information Systems Laboratory, Seelig has now become a mentor himself, teaching the next generation of scientists to keep hunting for answers among the helices.
“When he picks up the tune of a beautiful idea, he is unstoppable in crafting it into a compelling song,” Winfree said. “It’s been great how, after coming to UW, he has released album after album of hits.”
Those first “hits” were scrawled across whiteboards at Caltech. Seelig remembers poring over them with his collaborators, searching for that elegant solution, for theory to materialize into practice.
To the group’s surprise, their effort paid off more quickly than expected. For Seelig, it foreshadowed things to come.
“Shortly afterwards, we tested the idea experimentally,” Seelig said of inventing DNA strand displacement circuits. “It worked on the first try.” Read more →
Arvind Krishnamurthy (left) and Michael Taylor will lend their expertise to the ACE Center for Evolvable Computing, a multi-university venture focused on the development of microelectronics and semiconductor computing technologies.
Data centers account for about 2% of total electricity use in the U.S., according to the U.S. Office of Energy Efficiency and Renewable Energy, consuming 10 to 50 times the energy per floor space of a typical commercial office building. Meanwhile, advances in distributed computing have spurred innovation with the use of large, intensive applications — but at a high cost in terms of energy consumption and environmental impact.
A pair of Allen School professors will contribute to a multi-university effort focused on tackling these challenges in the distributed computing landscape. Arvind Krishnamurthy and Michael Taylor will lend their expertise to the ACE Center for Evolvable Computing, which will foster the development of computing technologies that improve the performance of microelectronics and semiconductors.
Funded by a $31.5 million grant from the Joint University Microelectronics Program 2.0 (JUMP 2.0), the ACE Center will advance distributed computing technology — from cloud-based datacenters to edge nodes — and further innovation in the semiconductor industry. Led by the University of Illinois Urbana Champaign and with additional funds from partnering institutions, the ACE Center will have a total budget of $39.6 million over five years.
“Computation is becoming increasingly planet-scale, which means not only that energy efficiency is becoming more and more critical for environmental reasons, but that we need to rethink how computation is done so that we can efficiently orchestrate computations spread across many chips distributed around the planet,” Taylor said. “This center is organizing some of the best and brightest minds across the fields of computer architecture, distributed systems and hardware design so that we may come up with innovative solutions.”
Krishnamurthy, the Short-Dooley Professor in the Allen School, is an investigator on the “Distributed Evolvable Memory and Storage” theme. His research focuses on building effective and robust computer systems, both in terms of data centers and Internet-scale systems. The ACE Center is not the only forward-looking initiative that is benefiting from Krishnamurthy’s expertise; he is also co-director of the Center for the Future of Cloud Infrastructure (FOCI) at the Allen School, which was announced last year.
“We are seeing an explosion of innovations in computer architecture, with a continuous stream of innovations in accelerators, programmable networks and storage,” Krishnamurthy said. “One key goal of this center is how to make effective use of this hardware and how to organize them in large distributed systems necessary to support demanding applications such as machine learning and data processing.”
Taylor, who leads the Bespoke Silicon Group at the Allen School, is an investigator in the “Heterogeneous Computing Platforms” theme. He’ll act as a fulcrum for research directions and guide a talented team of graduate students in designing distributed energy-efficient accelerator chips that can better adapt with ever-changing and more complicated computing environments.
“Today’s accelerator chips are very fixed function, and rapidly become obsolete, for example, if a new video encoding standard is developed,” Taylor said. “With some fresh approaches to the problem, accelerators in older cell phones would still be able to decode the newer video standards.”
Both Krishnamurthy and Taylor will contribute to the ACE Center’s goal to create an ecosystem that fosters direct engagement and collaborative research projects with industry partners drawn from SRC member companies as well as companies in the broader areas of microelectronics and distributed systems.
In addition to Taylor and Krishnamurthy at the University of Washington, other contributors to the ACE Center include faculty from the University of Illinois, Harvard, Cornell, Georgia Tech, MIT, Ohio State, Purdue, Stanford, the University of California San Diego, the University of Kansas, the University of Michigan and the University of Texas at Austin. Read more →
The Alfred P. Sloan Foundation has named the Allen School’s Leilani Battle (B.S., ‘11) a 2023 Sloan Research Fellow, a distinction that recognizes early-career researchers whose achievements place them among the next generation of scientific leaders in the U.S. and Canada. The two-year, $75,000 fellowships support research across the sciences and have been awarded to some of the world’s most preeminent minds in their respective fields.
“My research is not traditional computer science research so it’s wonderful to be recognized,” Battle said. “I strive to be myself in everything I do, so it’s awesome to see that others appreciate my unique perspective.”
Battle co-leads the Interactive Data Lab with Allen School colleague Jeffrey Heer, the Jerre D. Noe Endowed Professor of Computer Science & Engineering. Her research investigates the interactive visual exploration of massive datasets and stands at the intersection of several academic disciplines, including healthcare, business and climate science. In each, data-driven decisions continue to drive innovation across the globe.
“What piqued my interest in data science was the juxtaposition of the incredible power of existing tools and their underutilization by the vast majority of data analysts in the world,” Battle said. “Why are we not making better use of these tools? This sparked a multi-year journey to better understand why people use or don’t use various data science tools and how those tools could be made accessible to and effective for a wider range of users.”
While pursuing her doctorate at MIT, Battle developed ForeCache, a big data visualization tool that allows researchers to explore large amounts of data with greater ease and precision. Through machine-learning, ForeCache increased browsing speeds by reducing system latency by 88% when compared with existing prefetching techniques.
Since then, Battle has built upon her previous work in data visualization. In one study, she led an international team in creating the first benchmark to test how database systems evaluate interactive visualization workloads. In another, she and Heer investigated characterizing analyst behavior when interacting with data exploration systems, providing a clearer picture of how data is inspected and ultimately used through industry tools such as Tableau Desktop.
“I’m interested in not only streamlining the data science pipeline but also making it more transparent, equitable and accountable,” Battle said. “Some of my latest ideas are headed in this direction, where my collaborators and I are investigating how the concept of interventions in psychology and human computer interaction (HCI) could bring a new perspective to promoting responsible data science work.”
Battle is one of two UW researchers to be recognized in the latest class of Sloan Research Fellows, which also included Jonathan Zhu, a professor in the Department of Mathematics. Other recent honorees in the Allen School include professor Yulia Tsvetkov in 2022 and professors Hannaneh Hajishirzi and Yin Tat Lee in 2020.