When analyzing a large dataset, it can be overwhelming trying to figure out where to look for interesting insights. Visualizing the data can help, but manual chart specifications can also be a daunting and time-consuming task for users without extensive domain expertise. To help make datasets easier to understand and examine, in 2015, a team of researchers led by Allen School professor Jeffrey Heer introduced Voyager, a system that automatically generates and recommends charts and visualizations based on statistical and perceptual measures — allowing users to efficiently explore different parts of the dataset they may not have discovered before.
Since its release, Voyager has been called a “landmark development” and has helped transform visualization technology from human-led interactive visualization to a mixed-initiative approach. At IEEE VIS 2025 earlier this month in Vienna, Austria, Heer and his co-authors were recognized with the InfoVis 10-Year Test of Time Award for the Voyager paper’s lasting impact on the field. With the advancement and increasing popularity of artificial intelligence tools, the award committee noted, the system’s mixed-initiative approach is even more relevant today.
“The Voyager paper is exciting to me for many reasons. The work introduced a new approach to visualization recommendation and how to richly incorporate recommendations within user interfaces — all of which has proved influential to ongoing research,” said Heer, who holds the Jerre D. Noe Endowed Professorship in the Allen School. “To provide a solid representation for reasoning about visualizations and recommending charts, we also invented Vega-Lite, a high-level language for statistical graphics that went on to become a popular open source tool in its own right.”
Underlying Voyager is the Compass recommendation system which takes in user selections, data schema and statistical properties and generates suggested visualizations in the form of Vega-lite specifications. For example, an analyst looking at a dataset about cars can use Voyager to examine the effect of different variables such as horsepower, number of cylinders and acceleration. If the analyst is interested in looking at horsepower, they can browse charts with varied transformations of horsepower in the Voyager gallery and find the car with the highest horsepower. Voyager can also recommend visualizations with additional variables to help the analyst see if there are potential correlations or pursue other questions.
In a user study comparing Voyager to a visualization tool modeled after Tableau, the researchers found that Voyager helped users explore more of the data, leading to a significantly greater coverage of unique variable combinations.
Additional authors include Kanit Wongsuphasawat (Ph.D., ‘18), visualization team lead at Databricks; Dominik Moritz (Ph.D., ‘19), faculty at Carnegie Mellon University; Anushka Anand, director of product management at Salesforce; Jock Mackinlay, former technical fellow at Tableau; and Allen School adjunct faculty member Bill Howe, a professor in the University of Washington Information School.
At the Allen School, 22% of Fall 2025 undergraduate students are first generation, or one of the first in their family to pursue a bachelor’s degree. For first-gen students, navigating the twists and turns of higher education without a roadmap can be a daunting challenge — what are office hours? How do I choose the right courses for me? What do I do after college? Still, these students have persevered to figure it out on their own or leverage resources such as the Allen School’s first-gen student group, GEN1, to help them find their way.
In honor of the National First-Generation College Celebration on November 8, we asked students and faculty to share their experience being first and what advice they have for others still embarking on their first-gen journey. Here are some of their stories.
‘You made it here for a reason’: Kurtis Heimerl, professor
What does it mean to you and your family to be among the first to pursue a bachelor’s degree?
Kurtis Heimerl
Kurtis Heimerl: Not much! My parents didn’t really (and still don’t really) understand higher education and the value of it. There was an expectation of increased wages (which was true!) but not really a push to attend.
How has being first-gen influenced your studies or career path?
KH: Dramatically, I think. I worked in industry at points but I think the lack of college being a “normal” path meant that I didn’t leave when it was economically sensible to do so; instead, I stayed in and got more degrees (as those credentials are things that are hard to lose once you have them). I’m not sure I’d advise my children to go all the way to a Ph.D. but the journey obviously worked for me.
What are some of the most challenging or most rewarding parts about being first-gen?
KH: There’s a lot of imposter syndrome. The reality is that you made it here for a reason. It has been rewarding being able to give back to the community that supported you; I do a lot of work for UW because it was instrumental in my own success and it’s great to see it continue doing that for new students as well.
What advice would you give to first-gen students?
KH: That the doors are open. I personally have struggled with feeling like opportunities (research, internships, etc.) weren’t for me; it seemed like others slid in so naturally to these paths, but I felt like I didn’t understand a lot of the details or nuances to succeed. The reality is that no one really understood and everyone was figuring it out.
‘Your success multiplies far beyond yourself’: Sanket Gautam, master’s student, Professional Master’s Program
What does it mean to you and your family to be among the first to pursue a bachelor’s degree?
Sanket Gautam
Sanket Gautam: It means breaking generational barriers and transforming not just my future, but my entire family’s trajectory. Coming from an underrepresented community in India, my degree created financial sustainability that enabled me to support others in my family to explore opportunities they never imagined possible. This achievement represents the fulfillment of countless sacrifices and dreams from those who came before me. It carries both deep pride and the profound responsibility of being a catalyst for change in my community.
How has being first-gen influenced your studies or career path?
SG: Being first-gen taught me that creating opportunity means lifting others as I climb. Without a family roadmap, I learned to seek mentors, build networks, and advocate for myself in unfamiliar environments — experiences that shaped my commitment to serving as a GEN1 mentor and participating in GEN1 coffee chats. These skills developed through navigating my own journey now drive how I approach problem-solving and collaboration in my studies and career. My pursuit of AI specialization reflects a desire to build systems that expand access and empower underrepresented communities to thrive.
What are some of the most challenging or most rewarding parts about being first-gen?
SG: The challenge is navigating uncharted territory — creating your own path when there’s no family blueprint for financial aid, career planning, or institutional processes. You become your own guide, figuring out everything from networking strategies to academic decisions through trial, error, and determination. Yet this challenge builds incredible resilience and problem-solving skills that become your greatest assets. The reward is knowing your success multiplies far beyond yourself, opening doors and inspiring others in your family and community to pursue their own dreams.
What advice would you give to first-gen students?
SG: Your unique perspective is your strength — embrace it with confidence and pride. Seek out mentors, build community with fellow first-gen students, and never hesitate to ask questions, even when it feels intimidating. The path may feel uncertain at times, but every challenge you overcome builds the resilience that will carry you through future obstacles. Remember that by forging your own path, you’re not just succeeding for yourself — you’re creating a roadmap for everyone who comes after you.
‘You get to define your own path’: Czarin Dela Cruz, undergraduate student
What does it mean to you and your family to be among the first to pursue a bachelor’s degree?
Czarin Dela Cruz
Czarin Dela Cruz: Being among the first in my family to pursue a bachelor’s degree means making the most of the opportunities my family and I worked hard for after moving from the Philippines. Having access to more resources here motivates me to push forward and make my parents proud. It’s a way to honor their sacrifices and show that their efforts were worth it.
How has being first-gen influenced your studies or career path?
CD: Being first-gen has encouraged me to stand up for myself and always look toward the future. It’s motivated me to work hard in my studies and constantly find ways to improve. More importantly, it’s inspired me to pursue my passions not just for myself, but to honor the people who supported me and made it possible for me to be here.
What are some of the most challenging or most rewarding parts about being first-gen?
CD: One of the most challenging parts of being first-gen is navigating everything on your own — from understanding college systems to balancing academics and family expectations. But it’s also incredibly rewarding to see that your hard work pays off. Being first-gen means you get to define your own path, make your own choices, and work toward your goals for a brighter future.
What advice would you give to first-gen students?
CD: My advice to first-gen students is to never be afraid to ask for help. Communicate with those around you and reach out when you need support. There are so many people and resources ready to help you succeed. Being proactive opens doors to new opportunities, and you never know what meaningful connections or experiences you might discover.
Award winners and presenters, left to right: professor Shwetak Patel; Mark Nelson and Mike Fridgen, venture partners at Madrona Venture Group; Sabrina Albert, partner at Madrona Venture Group; Madrona Prize winner Yanming Wan; Madrona Prize runner-up Baback Elmieh; Madrona Prize runner-up Mateo Guaman Castro; Rasik Parikh and Rolanda Fu, investors at Madrona Venture Group.
From a robotic arm that learns how to pick up new objects in real time, to a model that converts 2D videos into 3D virtual reality, to a curious chatbot that adapts to its users, to machine learning techniques for decoding the brain (and so much more), the 2025 edition of the annual Research Showcase and Open House highlighted the breadth and depth of computing innovation coming out of the Allen School.
Last week, roughly 400 Industry Affiliate partners, alumni and friends gathered on the University of Washington campus to learn how the school is working toward solutions to a set of “grand challenges” to benefit society, in which the Allen School is uniquely positioned to lead; participate in technical sessions covering a range of topics, from artificial intelligence to sustainable technologies; and explore how researchers are leveraging machine learning to decode causality, learning and communication in the brain during a luncheon keynote; and learn about more than 80 research projects directly from the student researchers themselves at the evening poster session and open house — including those who walked away with the coveted Madrona Venture Prize or People’s Choice Award.
Unlocking the mysteries of brain learning with the help of machine learning
Allen School professor Matt Golub presenting his luncheon keynote on causality, learning and communication in the brain.
In his luncheon keynote, Allen School professor Matt Golub shared recent research from the Systems Neuroscience and AI Lab (SNAIL) that uses machine learning techniques to better understand how the brain performs computations such as decision-making and learning — insights that could, in turn, inform future developments in AI. Previous work has focused on reconstructing neuron connections ex vivo, or outside of the body, by looking at thin sections of the brain under a microscope. Instead, Golub and his team analyze active neural activity.
“If we can crack these problems, that will set us up in future work to understand how different brain networks perform distributed computation through their connections, through the dynamics of the activity that flows through those connections,” Golub said. “Then, we can ask how the connections change as the brain learns. We might be able to discover the learning rules that govern synaptic plasticity.”
Golub and his collaborators introduced a novel approach for analyzing neural population dynamics with optogenetics and computational modeling. Using lasers, the researchers targeted neurons to stimulate their activity; if they hit one neuron with the laser and another one fired reliably, they inferred a connection between the two. Because these experiments are resource intensive, the researchers designed an active learning algorithm that selected these stimulation patterns, or chose specific neurons to target with the laser, so that they could learn an accurate model of the neural network with as little data as possible.
Zooming out for a higher-level view, Golub and his team also developed a new machine learning method that can identify communication between entire regions of the brain. The technique, called Multi-Region Latent Factor Analysis via Dynamical Systems (MR-LFADS), uses multi-region neural activity data to untangle how different parts of the brain talk to each other. Unlike existing approaches, MR-LFADS observes what unobserved brain regions are likely saying as well — the team’s custom deep learning architecture can detect when a recorded region reflects an unobserved influence. When applied to real neural recordings, the researchers found that MR-LFADS could predict how disrupting one brain region would affect another, which were effects that the system had never seen before.
Moving forward, Golub said that he is thinking about “the nexus of these two fronts.” In particular, he is interested in advancing active learning in nonlinear models and other deep learning models that can help generate AI-guided causal manipulations — experiments where the model can tell researchers what data it needs to improve.
“All of this is aimed at trying to understand how our brains compute and learn to drive our flexible behavior, and advances there can and have inspired innovation in AI systems and for new approaches to improving the health and function of our brains,” Golub said.
‘Quite a lot of amazing research’
The event culminated with the evening poster session and announcement of the Madrona Prize, an annual tradition in which Madrona Venture Group recognizes innovative student research with commercial potential. Past award winners have gone on to raise hundreds of millions of dollars in venture capital and build companies that have been acquired by tech giants such as Google and NVIDIA.
Sabrina Albert, a partner in the firm, presented the 2025 prize to the winner and two runners-up.
“There is quite a lot of amazing research that you guys are working on, so it was quite a challenge to pick which ones were most exciting,” Albert said.
Yanming Wan presents his poster, which received the Madrona Prize, to attendees.
Allen School Ph.D. student Yanming Wan accepted the grand prize for CURIO, or Curiosity-driven User-modeling Reward as Intrinsic Objective. This new framework enhances personalization in large language models (LLMs) on multi-turn conversations.
Conversational agents need to be able to adapt to varying user preferences and personalities as well as diverse domains such as education or health care. However, conventional methods for training LLMs often struggle with personalization because they require pre-collected user data, making them less effective for new or content-limited users.
To solve this problem, Wan and the team introduced an intrinsic motivation reward model that enables LLMs to actively learn about the user out of curiosity and then adapt to their individual preferences during the conversation.
“We propose leveraging a user model to incorporate a curiosity-based intrinsic reward into multi-turn Reinforcement Learning from Human Feedback (RLHF),” said Wan. “This novel reward mechanism encourages the LLM agent to actively infer user traits by optimizing conversations to improve its user model’s belief. Consequently, the agent delivers more personalized interactions by learning more about the user across turns.”
Additional members of the research team include Allen School professor Natasha Jaques, Jiaxing Wu of Google DeepMind, Lior Shani of Google Research and Marwa Abdulhai, a Ph.D. student at University of California, Berkeley.
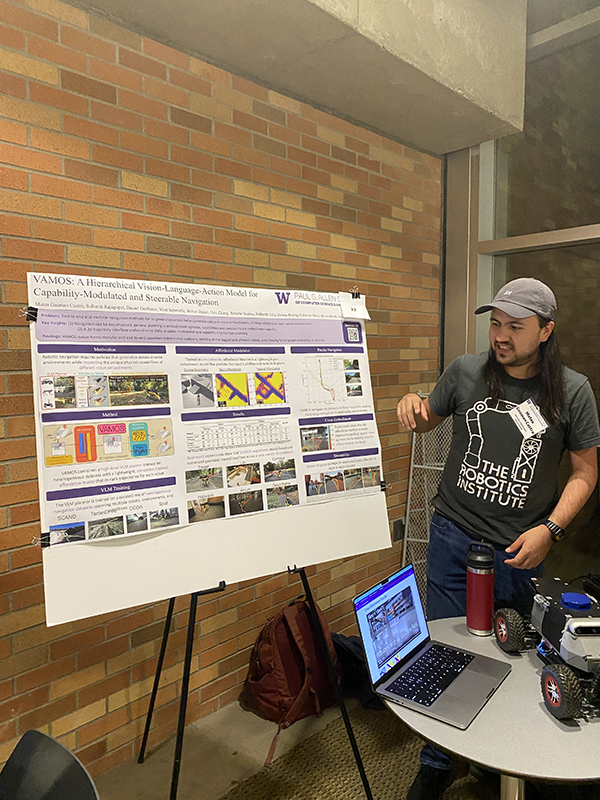
Madrona Prize Runner-up / VAMOS: A Hierarchical Vision-Language-Action Model for Capability-Modulated and Steerable Navigation
Mateo Guaman Castro showcases his poster.
Another research team received accolades for VAMOS, a hierarchical vision language-action (VLA) model that helps robots navigate across diverse environments. In both real-world indoor and outdoor navigation courses, VAMOS achieved a three times higher success compared to other state-of-the-art models.
“Contrary to the belief that simply scaling up data improves generalization, we found that mixing data from many robots and environments can actually hurt performance — since not all robots can perform the same actions or handle the same terrains,” said Allen School Ph.D. student Mateo Guaman Castro, who accepted the award on behalf of the team. “Our system, VAMOS, tackles this by decomposing navigation into a hierarchy: a high-level VLM planner proposes multiple possible paths, and a robot-specific ‘affordance modulator,’ trained safely in simulation, selects the path best suited to the robot’s physical abilities.”
Allen School researchers were also recognized for their research that transforms two-dimensional videos into a dynamic three-dimensional scene that users can experience in immersive virtual reality (VR) — revealing additional depth, motion and perspective.
“A key challenge is figuring out the 3D world from a single, flat video,” said Ph.D. student Baback Elmieh, who accepted the prize. “To address this, we first use an AI model to ‘imagine’ what the scene looks like from many different angles. We then use a new technique that models the scene’s overall motion while simultaneously fine-tuning the details in each frame. This combined approach allows us to handle fast-moving action, making progress towards reliving 2D videos or even historic moments as dynamic 3D experiences.”
Rounding out the evening was the announcement of the People’s Choice Award, where attendees voted for their favorite poster or demo.
People’s Choice Award presenter and winners, left to right: professor Shwetak Patel, Shirui Chen and Jiafei Duan.
Shwetak Patel, the Allen School’s director for development and entrepreneurship and the Washington Research Foundation Entrepreneurship Endowed Professor in Computer Science & Engineering and Electrical & Computer Engineering (ECE), presented the 2025 award to Allen School Ph.D. student Jiafei Duan and UW Department of Applied Mathematics Ph.D. student Shirui Chen for MolmoAct, an open-source action reasoning model developed by a team of UW and Allen Institute for AI (Ai2) researchers that enables robots to interpret and understand instructions, sense their environment, generate spatial plans and then execute them as goal-directed trajectories.
“MolmoAct is the first fully open action reasoning model for robotics. Our goal is to build generalist robotic agents capable of reasoning before they act — a paradigm that has already inspired a wave of subsequent research,” said Duan, who worked on the project as a graduate student researcher at Ai2.
The researchers invited attendees to test MolmoAct’s reasoning capabilities by putting an object in front of a robotic arm — such as a pen or a tube of lip gloss — and watching the robot learn to pick it up in real time.
Each year, the MIT Technology Review recognizes science and technology trailblazers whose work is helping solve global problems. Three members of the Allen School community were named part of this year’s MIT Technology Review Innovators Under 35 Asia Pacific — professors Simon Shaolei Du and Ranjay Krishna, along with alum Sewon Min (Ph.D., ‘24), now a faculty member at University of California, Berkeley and research scientist at the Allen Institute for AI (Ai2).
The three were recognized as pioneers for their innovative research that is advancing our understanding of artificial intelligence, large language models, computer vision and more.
Simon Shaolei Du: Tackling core AI challenges from a theoretical perspective
Simon Shaolei Du
Recent innovations in large-scale machine learning models have transformed data-driven decision making, from the rise of self-driving cars to ChatGPT. However, we still don’t understand exactly how these powerful models work, and Du is interested in unraveling some of the mysteries behind machine learning.
“My work focuses on building the theoretical foundations of modern artificial intelligence, establishing a systematic research path around deep learning’s trainability and generalization, as well as sample complexity in reinforcement learning and representation learning,” Du said.
Du’s research has already provided theoretical explanations for some of deep learning’s black boxes. He and his collaborators provided one of the first proofs for how over-parameterized machine learning models and neural networks can be optimized using a simple algorithm such as gradient descent. The researchers found that, with enough over-parameterization, gradient descent could find the global minima, or the point where the model has zero error on the training data, even if the objective function is non-convex and non-smooth. He also established the connection between deep learning and kernel methods, explaining how these models are able to generalize so well despite their large size. Beyond demystifying how these models work, Du is helping make over-parameterized models more mainstream. In 2022, he received a National Science Foundation CAREER Award to support his research in designing a resource-efficient framework to help make modern machine learning technologies more accessible.
He has also tackled core challenges in reinforcement learning, such as its high data requirements. Because agents learn through trial-and-error interactions with the environment, it can take many interactions, and data points, to build up a comprehensive understanding of the environment’s dynamics. To make the process more efficient, Du and his collaborators introduced a new algorithm to address an open problem on sample complexity that had remained unsolved for almost three decades. In their paper, the researchers prove that their algorithm can achieve optimal data efficiency and show that its complexity is not dependent on whether the planning horizon is long or short. Du also provided the first theoretical results showing that a good representation as well as data diversity are both necessary for effective pre-training.
Ranjay Krishna: Developing ‘visual thinking’ for vision-language models
Ranjay Krishna
Krishna’s research sits at the intersection of computer vision and human computer interaction and integrates theories from cognitive science and social psychology. Through this multidisciplinary approach, his work enables machines to learn new knowledge and skills through social interactions with people and enhances models’ three-dimensional spatial perception capabilities.
“I design machines that understand the world — not just by recognizing pixels, but by reasoning about what they see, where they are and how to act to change the world around them,” said Krishna, who directs the UW RAIVN Lab and leads the PRIOR team at Ai2.
Krishna addresses large vision-language models’ deficiencies in compositional reasoning due to their inability to combine learned knowledge on the spot to handle new problems. Krishna proved that simply scaling up the models is not an effective solution. Instead, he and his collaborators introduced an iterated learning algorithm which is inspired by the cultural transmission theory in cognitive science. This method periodically resets and retrains the model, encouraging visual representations to evolve toward compositional structures. By combining this technique with the PixMo dataset, Krishna helped develop the Molmo series of models, Ai2’s family of open source and state-of-the-art multimodal models that can both understand and generate content using text and images.
He is also interested in tackling multimodal models’ challenges with spatial reasoning. While these models can often perform well in basic tasks like object detection, they struggle with tasks requiring a deeper understanding of geometric transformations and spatial context, such as sketching. Krishna and his collaborators developed Sketchpad, a framework that gives multimodal language models a visual sketchpad and tools to draw on it. Using this technique, a model can “think visually” like humans can by sketching with auxiliary lines and marking boxes, which helps it improve its reasoning accuracy and break down complex spatial and mathematical problems. He has taken this approach a step further with a training method that augments multimodal language models with perception tokens, improving their three-dimensional spatial perception.
Krishna has received the 2025 Samsung START Faculty Award to study “Reasoning with Perception Tokens” as well as the 2024 Sony Faculty Innovation Award to research “Agile Machine Learning,” in addition to his TR35 Asia Pacific recognition.
Sewon Min: Enabling models to find answers from the external world
Sewon Min
Min aims to build the next generation of AI systems that feature flexibility, superior performance and increased legal compliance. In her Allen School Ph.D. dissertation, she tackled fundamental challenges that current language models (LMs) face, such as factuality and privacy, by introducing nonparametric LMs. Her other work has only further driven the development of more open, controllable and trustworthy LMs.
“My research explores new ways of building models that use data creatively — for instance, by using retrieval (nonparametric LMs) and by designing modular LMs trained in a non-monolithic manner,” Min said.
Min has advanced retrieval-augmented and nonparametric language models on different fronts. She and her collaborators scaled a retrieval datastore, MassiveDS, to more than one trillion tokens — the largest and most diverse open-source datastore to date. The researchers also found that increasing the scale of data available at inference can improve model performance on various downstream tasks, providing a path for models to move from parametric memory toward data pluggability. At the systems interface level, Min helped develop REPLUG, a retrieval-augmented language modeling framework that augments black-box LMs with a tuneable retriever. This simple design can be applied to existing LMs and helps improve the verifiability of text generation.
She has also developed techniques to address reliability issues and legal risks that LMs run into. While the legality of training models on copyrighted or other high-risk data is under debate, model performance significantly declines when only trained on low-risk texts due to the limited size and domain coverage, Min and her collaborators found. So the researchers introduced the SILO framework, which manages the risk-performance tradeoff by putting high-risk data in a replaceable datastore. To help quantify the trustworthiness of LM generated text, Min developed FACTSCORE, a novel evaluation that breaks a generation down into atomic facts and then computes the percentage of these facts that are corroborated by a reliable knowledge source. Since its release, the tool has been widely adopted and used to evaluate and improve the reliability of long-form LM text generation.
Every year, as the amount of data we create grows and software becomes increasingly more complex, it is more crucial to improve the efficiency of computer systems. However, in this complex ecosystem, dependability, such as ensuring software contains fewer bugs and achieves greater security, is often considered an afterthought, said Allen School professor Baris Kasikci. Software and hardware have been plagued by bugs that can lead to data loss, security vulnerabilities and costly critical infrastructure failures.
In his research, Kasikci focuses on developing techniques for building systems that are both efficient and have a strong foundation of dependability, with an emphasis on real-world technical and societal impact. At the 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2025) in June, Kasikci was recognized with the Rising Star in Dependability Award for “his impressive track-record and contributions in the field of dependable systems, including multiple publications in highly regarded venues, and influence on current industry practice.”
“Building systems that are simultaneously efficient and dependable is challenging because there is a strong tension between techniques aimed to achieve these properties,” said Kasikci. “This tension is due to the different trade-offs involved in achieving efficiency and dependability (e.g., performance optimizations versus defenses against vulnerabilities that cause slowdown). To rise to this challenge, my work draws insights from a broad set of disciplines such as systems, computer architecture, programming languages, machine learning and security.”
Kasikci’s work helps improve society’s trust in computer systems with new secure hardware systems and bug detection techniques. He was part of the team that discovered Foreshadow, a speculative attack on Intel processors which enables an attacker to steal sensitive information that is stored inside personal computers and third-party clouds. Their work has influenced the redesign of Intel processors and motivated all major cloud vendors to deploy mitigations against the vulnerability. He and his collaborators also developed REPT, which is one of the most widely-deployed failure analysis systems in the world and is in use across all modern Microsoft Windows platforms. It has allowed Microsoft engineers to tackle bugs that have been open for many years, and the techniques behind the system have been adopted by both Intel and Facebook.
He is also interested in developing methods for optimizing the entire computing stack, from hardware to operating systems. At the hardware level, Kasikci helped introduce techniques to improve code, such as Ripple, a software-only technique that uses program context to inform the placement of cache eviction instructions. More recently, he developed new methods for making systems that support large language models more efficient including NanoFlow, a novel LLM-serving framework with close to optimal throughput.
In future work, Kasikci is interested in advancing reliability techniques such as debugging and testing by making production execution data such as logs and core dumps more useful. For example, he envisions using this information to quickly find bugs that production systems may suffer from, while also managing how much storage and resources these logs can consume.
Networks have become one of the foundational pillars for modern society. When they go down, we cannot fly airplanes, operate bank accounts or even scroll through social media. One of the long-standing challenges in networking, however, is the difficulty of accurately predicting how changes to device configurations will impact real-world traffic flows — especially when a single code line revision can easily break a network, explained Allen School professor and alum Ratul Mahajan (Ph.D., ‘05).
To help network engineers and operators ensure that their networks operate exactly as they intend, Mahajan and his collaborators introduced Batfish, an open source network configuration analysis tool that can find errors and ensure the accuracy of planned network configurations, helping to prevent costly outages. At the ACM Special Interest Group on Data Communication (SIGCOMM) conference last month, Batfish was recognized with the SIGCOMM Networking Systems Award for its “significant impact on the world of computer networking.”
“Over the years, networks have become super complicated and it has gotten to the point where humans cannot assure that changes they make to the network are not going to bring it down,” said Mahajan, who is one of the co-directors for the UW Center for the Future of Cloud Infrastructure (FOCI). “With Batfish, we focus on what we call proactive validation. Instead of, after the fact, discovering that something bad has happened to the network, Batfish takes your planned change to the network and makes a model of how the network will behave if this change were to go through.”
The platform was first developed in 2015 by Mahajan and colleagues at Microsoft Research; University of California, Los Angeles; and University of Southern California. It was later commercialized by Intentionet, where Mahajan was the CEO and co-founder. Today, Batfish is managed by Amazon Web Services (AWS), and more than 75 companies rely on the tool to help design and test their networks.
Batfish uses an offline “snapshot” of the network to build a model and infer if there are any issues present within the configuration. The platform takes in device configurations from various vendors including Cisco, Juniper and Arista, and it then converts these configurations into a unified and vendor-independent model of the network. Once the model is built, engineers can query Batfish about topics such as the reachability between various network parts, potential routing loops, access control list (ACL) configurations such as incorrectly assigned permissions, or other policy and security constraints. Batfish then provides specific information needed to find and fix the misconfigurations.
While Batfish’s main architecture and original goal has stood the test of time, many of its underlying techniques have been revamped and enhanced to tackle scalability and usability challenges that complex, real-world networks face. For example, for each violated property, Batfish originally only provided one counterexample packet that was randomly picked by the SMT solver from violating headspace, however, these counterexamples lacked context and could be confusing. To help engineers understand what went wrong, Batfish now provides a positive example, or a packet that does not violate the property, alongside a counterexample that engineers can compare to pinpoint the issue.
As one of the earliest and most widely-adopted network verification platforms, it has helped shape key areas of research such as control-plane and data-plane modeling and network automation. From tech giants to small startups, multiple organizations rely on Batfish every day to both validate network configurations and drive innovations in network designs and operations.
“The main lasting impact of Batfish, beyond the code itself, would be changing the practice of networking to use these types of tools,” Mahajan said. “It was one of the first pieces of technology that made automated reasoning for networks a reality.”
Akari Asai (Ph.D., ‘25), research scientist at the Allen Institute for AI (Ai2) and incoming faculty at Carnegie Mellon University, is interested in tackling one of the core challenges with today’s large language models (LLMs). Despite their increasing potential and popularity, LLMs can often get facts wrong or even combine tidbits of information into a nonsensical response, also known as hallucinations. This can be especially concerning when these LLMs are used for scientific literature or software development, where accuracy is vital.
For Asai, the solution is developing retrieval-augmented language models, a new class of LLMs that pull relevant information from an external datastore using a query that the LLM generates. Her research has helped establish the foundations for retrieval-augmented generation (RAG) and showcase its effectiveness at reducing hallucinations. Since then, she has gone on to add adaptive and self-improvement capabilities and apply these innovations to practical applications such as multilingual natural language processing (NLP).
Asai was recently named one of MIT Technology Review’s Innovators Under 35 2025 for her pioneering research improving artificial intelligence. The TR35 award recognizes scientists and entrepreneurs from around the world who “stood out for their early accomplishments and the ways they’re using their skills and expertise to tackle important problems.”
“With the rapid adoption of LLMs, the need to investigate their limitations, develop more powerful models and apply them in safety-critical domains has never been more urgent,” said Asai.
Traditional LLMs generate responses to user inputs based solely on their training data. In comparison, RAG enhances the LLM with an additional information retrieval component that utilizes the user input to first pull information from a new, external datastore. This allows the model to generate responses that incorporate up-to-date information without needing additional training data. By checking this datastore, an LLM can better detect when it is generating a falsehood, which it can then verify and correct using the retrieved information.
Asai took that research a step further and she and her collaborators introduced Self-reflective RAG, or Self-RAG, that improves LLMs’ quality and factual accuracy with retrieval and self-reflection. With Self-RAG, a model uses reflection tokens to decide when to retrieve relevant external information and critique the quality of its own generations. While RAG can only retrieve relevant information a fixed number of time steps, Self-RAG can retrieve multiple times — making it useful for diverse downstream queries including instruction following.
She is interested in utilizing these retrieval-augmented language models to solve real-world problems. In 2024, Asai introduced OpenScholar, a new model that can help scientists more effectively and efficiently navigate and synthesize scientific literature. She has also investigated how retrieval-augmented language models can be useful for code generation, and helped develop frameworks that can improve information access across multiple languages such as AfriQA, the first cross-lingual question answering dataset focused on African languages.
“Akari is among the pioneers in advancing retrieval-augmented language models, introducing several paradigm shifts in this area of research,” said Allen School professor Hannaneh Hajishirzi, Asai’s Ph.D. advisor and also senior director at Ai2. “Akari’s work not only provides a foundational framework but also highlights practical applications, particularly in synthesizing scientific literature.”
This award comes on the heels of another MIT Technology Review recognition. Last year, Asai was named one of the publication’s Innovators Under 35 Japan. She has also received an IBM Ph.D. Fellowship and was selected as one of this year’s Forbes 30 Under 30 Asia in the Healthcare and Science category.
At the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), Allen School researchers brought home multiple awards for their work that is moving natural language processing research forward. Their projects ranged from laying the foundation for how artificial intelligence systems understand and follow human instructions to exploring how large language models (LLMs) pull responses from their training data — and more.
TACL Test of Time Award: Weakly Supervised Learning of Semantic Parsers for Mapping Instructions to Actions
From robotics to voice assistants, today’s AI systems rely on their ability to understand human language and interact naturally with it.
Luke Zettlemoyer
In their 2013 paper “Weakly Supervised Learning of Semantic Parsers for Mapping Instructions to Actions,” Allen School professor Luke Zettlemoyer and then student Yoav Artzi (Ph.D., ‘15), now a professor at Cornell Tech, set the groundwork for this capability with an approach for teaching models to follow human instructions without the need for detailed manual explanations. For their lasting contributions to the field, the researchers received the Test of Time Award as part of the inaugural Transactions of the Association for Computational Linguistics (TACL) Paper Awards presented at ACL 2025.
“This was the first paper in a line of work on learning semantic parsers from easily gathered interactions with an external world, instead of requiring supervised training data,” Zettlemoyer said. “Although the form of the models has changed significantly over time, this style of learning is still relevant today as an early precursor to techniques such as Reinforcement Learning with Verifiable Rewards (RLVR).”
Zettlemoyer and Artzi developed the first comprehensive model that tackles common issues that arise with learning and understanding unrestricted natural language. For example, if you told a robot to follow the navigation instructions “move forward twice to the chair and at the corner, turn left to face the blue hall,” it would need to solve multiple subproblems to interpret the instructions correctly. It would have to resolve references to specific objects in the environment such as “the chair,” clarify words based on context, and also understand implicit requests like “at the corner” that provide goals without specific steps.
To address these challenges without the need for intensive engineering effort, the duo developed a grounded learning approach that can jointly reason about meaning and context, and then continue to learn from their interplay. It uses Combinatory Categorial Grammar (CCG), which is a framework that assigns words to different syntactic categories such as noun or prepositional phrase, efficiently parsing complex instructional language for meaning by mapping them into logical expressions. Then, the weighted CCG ranks possible meanings for each instruction.
This joint model of meaning and context allows for the system to continue to learn from situated cues, such as the visible objects in the environment. For example, in the earlier set of navigation instructions, “the chair” can refer to multiple different objects such as chairs, barstools or even recliners. While the CCG framework would include a lexical item for each meaning of “the chair,” the execution of the task might fail depending on what objects are in the world. It allows for the system to learn by watching examples play out, and then following if the actions lead to successful outcomes such as completing the task or reaching a destination.
The researchers tested their method using a benchmark navigational instructions dataset and found that their joint approach successfully completed 60% more instruction sets compared to the previous state-of-the-art methods.
Outstanding Paper Award: Byte Latent Transformer: Patches Scale Better Than Tokens
Allen School Ph.D. students Artidoro Pagnoni and Margaret Li earned an ACL Outstanding Paper Award for research done at Meta with their advisor Zettlemoyer, who is also the senior research director at Meta FAIR.
Alongside their collaborators, they introduced the Byte Latent Transformer (BLT), a new byte-level LLM architecture that is the first to be able to match the more standard tokenization-based LLM performance at scale. At the same time, BLT is also able to improve efficiency and increase robustness to noisy data.
Many existing LLMs are trained using tokenization, where raw text is broken down into more manageable tokens which then serve as the model’s vocabulary. This process was essential because training LLMs directly with bytes was cost prohibitive at scale. However, these tokens can influence how string is compressed and lead to issues such as domain sensitivity.
Instead, BLT groups bytes into dynamically-sized patches, serving as the primary units of computation. These patches are then segmented based on the entropy of the next byte, allowing the system to allocate more model capacity where needed. For example, higher entropy indicates a more complex sequence which can then prompt a new, shorter patch. In the first Floating-Point Operations (FLOP) controlled scaling study of byte-level models, the team found that BLT’s performance was on par or superior to models such as Llama 3. With its efficiency and adaptability, the researchers position BLT as a promising alternative to the traditional token-based models available.
As LLMs become increasingly popular in higher-stake scenarios, it is important to understand why they generate certain responses and where they get their answers from. Fully open language models such as OLMo have been trained on trillions of tokens that everyone can access, but current behavior tracing methods are not scaled to work within this multi-trillion-token setting.
To address this, a team of researchers at the Allen School and the Allen Institute for AI (Ai2) introduced OLMoTrace, the first system that allows users in real time to explore how LLM outputs connect back to their training data. For the research’s innovation and practical application, the team received the ACL 2025 Best Demo Paper Award.
Jiacheng Liu
“Today’s large language models are so complex that we barely understand anything about how they generate the responses we see,” said lead author and Allen School Ph.D. student Jiacheng Liu. “OLMoTrace is powered by a technology I previously developed at UW, ‘infini-gram,’ with numerous system optimizations enabling us to deliver instant insights to how LLMs likely have learned certain phrases and sentences.”
The OLMoTrace inference pipeline works by scanning the LLM’s output and identifying long, unique and relevant text spans that appear verbatim in the model’s training data. For each span, the system retrieves up to 10 snippets from the training data that contain the span, prioritizing the most relevant documents. Finally, the system does some post-processing on the spans and document snippets, and presents them to the user through the chat interface. OLMoTrace is publicly available in the Ai2 model playground with the OLMo 2 family of models.
The researchers proposed multiple practical applications for OLMoTrace. For example, if the model generates a fact, users can look back to the training data to fact check the statement. It can also reveal the potential source of seemingly creative and novel LLM-generated expressions. In addition, OLMoTrace can help debug erratic LLM behaviors, such as hallucinations or incorrect self-knowledge, which are crucial to address as LLMs become increasingly more commonplace, Liu explained.
ACL Dissertation Award: Rethinking Data Use in Large Language Models
For her Allen School Ph.D. dissertation titled “Rethinking Data Use in Large Language Models,” Sewon Min, now faculty at University of California, Berkeley, received the inaugural ACL Dissertation Award. In her work, Min tackled fundamental issues that current language models face, such as factuality and privacy, by introducing a new class of language models and alternative approaches for training such models.
This new class of models, called nonparametric language models, is able to identify and reason with relevant text from its datastore during inference. Compared to conventional models that have to remember every applicable detail from their training set, models with a datastore available at inference time have the potential to be more efficient and flexible.
Nonparametric language models can also help address the legal constraints that traditional models often face. Language models are commonly trained using all available online data, which can lead to concerns with copyright infringement and crediting data creators. Min developed a new approach where language models are trained solely on public domain data. Copyrighted or other high-risk data is then kept in a datastore that the model can only access during inference and which can be modified at any time.
Each year, Qualcomm recognizes exceptional Ph.D. students whose research proposals promote the company’s core values of innovation, execution and teamwork with the Qualcomm Innovation Fellowship. With the goal of enabling “students to pursue their futuristic innovative ideas,” the winning teams receive a one-year fellowship as well as mentorship from Qualcomm engineers to help their projects succeed.
Two of this year’s winning teams from North America feature Allen School students. Andrew Alex and Megan Frisella received support for their proposed project “Productive Programming of Multi-Threaded Hardware Accelerators.” Fellow Allen School Ph.D. student Zixian Ma and Yushi Hu, a Ph.D. student in the University of Washington’s Department of Electrical & Computer Engineering (ECE), also earned a fellowship for their project “Learning Multi-modal Agents to Reason and Act for Complex Multi-modal Tasks.”
Productive Programming of Multi-Threaded Hardware Accelerators
Andrew Alex
The hardware landscape of modern systems-on-chips (SoCs), which are made of a variety of digital signal processors (DSP), graphic processing units (GPU) and differing sizes of general purpose cores, is constantly evolving. Because each new generation of hardware requires an optimized kernel library to ensure that their machine learning and signal processing workloads run smoothly and efficiently, it can be difficult for performance engineers to keep up.
Performance engineers are turning to user-scheduled languages (USL), an emerging class of programming languages designed for heterogeneous hardware. They work by dividing the algorithm that specifies the program’s functional behavior from the schedule, which defines how that computation is carried out. Alex and Frisella aim to build a language system that is an extension of Exo, a popular USL that can optimize high-performance computing kernels on to new hardware accelerators, but lacks support for asynchronous parallelism or concurrency. Their proposed language system is capable of scheduling programs to exploit asynchronous and concurrent SoC targets, while also ensuring that the program’s behavior is preserved
Megan Frisella
“The tools for producing the highly-performant code that is important for fields like machine learning and signal processing have not kept pace with the ever-expanding capabilities of the hardware that runs the code,” said Alex, who is advised by Allen School professor Gilbert Bernstein. “Our project aims to remedy this gap by enabling a programmer to express this highly-performant, concurrent code as a sequence of equivalence-preserving transformations of a sequential program.”
Using such a system, performance engineers will not be limited to choices made by the optimizing compiler to transform their code using a cost model that may not reflect all the newly available features in the hardware it is targeting. Instead, engineers can apply their own domain and hardware-specific knowledge to the problem without existing tools such as compilers getting in the way — helping them write code faster and with less effort.
“Extending the power of user-scheduling to asynchronous and concurrent SoCs will unlock productivity in programming emerging hardware,” said Frisella, who is co-advised by Bernstein and faculty colleague Stephanie Wang.
Learning Multi-modal Agents to Reason and Act for Complex Multi-modal Tasks
Zixian Ma
Real-world multi-modal foundation models can help with various tasks ranging from answering simple visual questions about objects in daily life to solving more difficult problems about travel planning. Although these state-of-the-art models can answer generic and straightforward questions well, they struggle with complex questions and with generalizing about new tasks. For example, a user may take a picture of a panel showing different gas prices and ask the model how many gallons they can buy within a certain budget, but the model will have trouble answering.
To address these challenges, Ma and Hu propose to develop multi-modal agents that can explicitly reason about and act on these complex tasks using chains-of-thought-and-action. They aim to curate a new dataset with images from across various domains — such as daily life images, web screenshots and medical images — and pair it with a novel learning method.
“Our work aims to enhance open-source foundation multi-modal models’ capabilities to not only perform complex tasks through reasoning and actions but also do so in a more interpretable manner,” said Ma, who is co-advised by Allen School professor Ranjay Krishna and professor emeritus Daniel Weld.
With the large-scale dataset, Ma and Hu plan to train generalizable multi-modal agents using heterogeneous pretraining and domain-specific supervised finetuning and reinforcement learning. The researchers will build a similar architecture to that of heterogeneous pretrained transformers, which are able to combine a huge amount of data from multiple sources into one system to teach a robot an array of tasks using stems, trunks and heads.
Yushi Hu
In their proposed system, each stem features a domain-specific vision encoder that maps the visual data from various domains to visual features, or the numerical representations of an image’s visual content. The shared trunk is a transformer encoder block which connects these domain-specific visual features to shared representations in the same dimension of the text embeddings. Then the shared head, which is a decoder-only language model, takes both the visual tokens from the shared encoder as well as the text tokens of the input query, and generates the next set of text tokens following the inputs.
“This research focuses on developing artificial intelligence that can seamlessly understand, reason and generate across vision, language, audio — mirroring the way people interact with the world. By unifying these diverse streams, we aim to move beyond passive chatbots toward truly helpful agents that collaborate with humans and complete real-world tasks,” said Hu, who is co-advised by Allen School professor Noah A. Smith and ECE professor Mari Ostendorf.
The Allen School-affiliated teams are among three UW winners of the Qualcomm Innovation Fellowship this year. They are joined by ECE Ph.D. students Marziyeh Rezaei and Pengyu Zeng, who earned a fellowship to pursue their research proposal titled “Ultra-low Power Coherent Front-haul Optical Links to enable multi-Tb/s Capacity for 6G Massive MIMOs and Edge AI Datacenters.”
Rules are vital for building a safe and healthy functioning online community, and Reddit is no exception. For community moderators, however, it can be difficult to make data-driven decisions on what rules are best for their community.
A team of researchers in the Allen School’s Social Futures Lab and Behavioral Data Science Lab conducted the largest-to-date analysis of rules on Reddit looking at over 67,000 rules and their evolution across more than 5,000 communities over a period of five years — accounting for almost 70% of all content on the platform. This study is the first to connect Reddit rules to community outcomes. They found that rules on who participates, how content is formatted and tagged as well as rules about commercial activities were the most strongly associated with community members speaking positively about how their community is governed.
“This was my first paper, and I am extremely grateful for it to be named best paper of ICWSM 2025,” said lead author Leon Liebmann (B.S., ‘25), now at the online privacy company Westbold. “The work was difficult at times, and my advisors and co-authors Allen School Ph.D. student Galen Weld and professor Tim Althoff provided me with the direction and methods I needed to get it done. These people shaped my time in the Allen School and gave me a love for research I’d love to revisit.”
To better understand the rules on Reddit, the team first had to map out which communities had what rules and when. The researchers developed a retrieval-augmented GPT-4o model to classify rules into different categories based on their target, tone and topic. They then assessed the rules based on how common they were and how they varied across different communities, and also collected timelines on how the communities’ rules changed over time. At the same time, the researchers used a classification pipeline to identify posts and comments discussing community governance.
Taken together, this study can help inform Reddit moderators and community leaders on what rules their communities should have. The researchers found that the most common rules across communities covered post content, spam and low quality content, and respect for others — guidelines that platforms could use to create “starter packs” for new communities. They also found that how moderators word rules could influence how positively or negatively communities view their governance. For example, prescriptive rules, or those that describe what community members should do, are viewed more favorably than restrictive rules that focus on what community members should not do. By choosing to phrase rules prescriptively, moderators can help communities have a positive view of their governance.
In addition to Leibmann, Weld and Althoff, Allen School professor Amy X. Zhang was also a co-author on the paper.