Last spring, Newport High School student Sophia Lin of Bellevue, Washington, was eager to start coding. Having applied to several summer coding programs, she was ready to learn. Unfortunately, as the pandemic spread, they were all canceled. Seeing her younger sister’s disappointment, Allen School senior Elizabeth Lin decided to be her coding teacher. With the help of her twin sister Christin, a senior in the University of Washington’s Department of Electrical & Computer Engineering, the two created a virtual summer coding program. Then they invited 300 kids from around the world to join them, free of charge
“As a teaching assistant in the Allen School’s Intro to Programming course, I had already taught hundreds of students how to code so I knew I could teach her, too,” said Elizabeth. “But knowing I had a busy summer with an internship at Microsoft as a software engineer, I decided to record the lessons. That way, I could teach others, too.”
Christin Lin
The two sisters reached out to their contacts from area high schools and advertised on Facebook to recruit 6th through 12th grade students interested in their new initiative, STEM League Developer Program, an offshoot from an outreach program the two started in high school.
“As big advocates for STEM education, we previously co-founded STEM League, an organization we started in high school with the mission to promote STEM opportunity and awareness to students in our local community,” said Christin. “Through STEM League, we hosted a series of STEM outreach programs at local libraries, facilitated Seattle STEM company tours, and volunteered for STEM events at local elementary schools. We wanted to continue that mission, therefore we launched the STEM League Developer Program.”
And within two weeks of recruiting students, the Lins had students from around the world signed up for the program with sponsorship from T-Mobile.
“The exponential interest in the Seattle area and around the world amazed us, but also brought some concerns,” said Elizabeth. “We worried about making sure every student had a quality experience. Learning to code can be daunting by yourself, and we wanted to ensure each student had support throughout the 8 weeks.”
From left to right: Elizabeth, Sophia and Christin Lin
The Lins once again returned to social media to recruit mentors — experienced high school and college programmers willing to work with the students. In about a month, the two screened and interviewed 50 mentors. By the end of June, they enrolled 300 students. Each mentor was assigned seven students to help, in various time zones across the world.
“Greg and I are thrilled when our interdisciplinary, hands-on entrepreneurship course contributes in at least some small way to giving students the inspiration and courage to head out and do remarkable things,” said Lazowska. “And what Elizabeth and her team have accomplished is truly remarkable.”
From Harry Potter-themed coding competitions, to a two-week program-wide hackathon where students created their own projects, to using Discord so everyone could stay in touch easily, the Lins and their collaborators found new and exciting ways to engage students and make coding more relevant to them.
“I thought the STEM League Developer Program was really fun, and it was definitely the highlight of my summer. I learned many important coding skills that I can now leverage for my future,” said one 10th grade participant. “Not only did I grow as a developer, I grew as a person, as I learned life skills like tenacity, motivation, and perseverance. The Discord community and the mentors were very supportive of everyone’s needs and helped create a positive learning environment where everyone could grow.”
Parents noticed how much their kids were enjoying the program. Several wrote in to thank the Lins and the mentors for teaching their kids during a particularly hard summer.
“My kids have been doing some other coding classes on a regular basis. But what they have learned at STEM League is of far better quality and better retained than any of those outside classes,” noted the parent of a student in Bellevue. “On top of it all they are having a lot of fun and they look forward to the next lesson. I don’t even have to keep nagging them to do it.”
According to Christin, the twins always wanted to host coding classes for students. They intend to continue the program next summer after they graduate.
Both sisters and five of the mentors in the program are alumni of the UW College of Engineering’s Washington State Academic RedShirt (STARS) program, a two-year specialized curriculum designed to build learning skills and strengthen academic preparation for core math and science prerequisites.
“This coding program idea sparked back in 2018, but we never found the time to do it,” she said. “However, this summer, we decided to launch it because we are both interested in entrepreneurship and experiencing something created by ourselves from scratch.”
UW, TCN and Althea members successfully deployed the first LTE in the Hilltop neighborhood of Tacoma last month.
While the internet is so critical for employment, education and communication, millions of Americans in rural and urban areas still do not have access to affordable connections. This lack of access further contributes to digital and economic inequality, especially during a pandemic when many schools and jobs have been moved online. A team of University of Washington researchers led by professor Kurtis Heimerl and Ph.D. student Esther Jang of the Allen School’s Information & Communications Technology for Development Lab are helping to address this problem right here in Washington.
With support from the Public Interest Technology University Network (PIT-UN), the group — which includes UW Tacoma urban studies professor Emma Slager and Jason Young, a senior research scientist in the iSchool — is deploying networks that will bring new, inexpensive, community-owned connectivity to marginalized communities in Seattle and Tacoma. The UW is one of 25 universities to receive a PIT-UN grant, which was created to fund critical research and build an inclusive career pipeline to advance the field of public interest technology.
Community cellular networks are owned and operated by the community they serve with the help of public and local organizations such as schools, nonprofits, community centers, makerspaces, libraries, small businesses, and tiny house villages. Leveraging their expertise in working with community cellular networks internationally, the team deployed a new network with a local connectivity non-profit, the Tacoma Community Network (TCN), to bring inexpensive, community-owned connectivity to the Hilltop community in the third largest city in Washington.
Bee Ivey, TCN’s volunteer executive director, said that as a nonprofit cooperative, TCN can focus on great speed and service without worrying about pleasing shareholders. To be sustainable, TCN needs about 20-25 members per “gateway,” which is an access point from which internet connectivity is distributed to the community. The partnership with the UW will empower TCN to connect more individuals at a lower price, which in turn allows them to get even more low income and extremely low income households online. Although the project is focused on making digital connections, it turns out that a personal touch was critical to making it work.
“We did a lot of canvassing prior to the pandemic, which allowed us to really connect with residents of Hilltop. One of the great things about being face-to-face is that you get to know people and hear their stories about how the internet affects their lives,” said Ivey. “It was truly eye-opening for us to meet so many people who didn’t have internet and had no way to access it, and definitely brought the statistics and research we’d seen to life.
Up to a quarter of all urban residents don’t have internet access, according to some studies, Ivey said, and it was made very clear the ways in which people are held back from living full, productive and satisfying lives when they lack internet access. Hearing these stories definitely strengthened the team’s resolve to continue the work connecting everyone to the internet. Now with the pandemic, they are focused on social media and networking, along with mailers to help reach more people who need internet access.
UW, TCN and Althea members built and deployed an LTE in Hilltop, in Tacoma
In Tacoma, one LTE network deployed in November contains eight households and is growing. Althea, a software company that makes mesh networking technology in which TCN’s routers use blockchain-based micro-payments to pay each other for traffic forwarding, is supporting the project. It has set up community wireless mesh networks all over the world, and is interested in integrating with LTE.
“Although we had a modest start, it represents a 30 percent adoption rate among the houses we were immediately able to reach,” said Ivey. “With the University of Washington’s help, we will be able to expand the number of households within our reach, as well as offer different types of internet connections — both typical wireless ISP equipment and LTE, the same data network used by cell phones. While there are many fantastic community-based internet networks out there, this particular type has never been deployed before in the United States to my knowledge, and it will make it far easier for individuals to access the internet.”
UW spun out the Local Connectivity Lab to deploy the LTE networking technology, powered by open-source software and operating in the Citizen’s Band Radio Service frequency spectrum, which is open enough to allow unlicensed devices to transmit in much of Seattle and Tacoma. This will allow the researchers to run open-sourced cellular networks in the U.S. on a small community scale.
“Cellular networks, with their higher-power access points, more favorable spectrum, and more efficient waveforms, have a much wider coverage area and user capacity than typical WiFi networks, and are also designed for user mobility like cell phones,” said Esther Jang, an Allen School graduate student leading the project. “Some initial line-of-sight link performance tests from our test deployment at UW yielded 60 megabits per second down and eight Mbps up with Consumer Premises Equipment, like a stationary user device with our SIM card at 1.3 miles away, from a backhaul connection around 150 Mbps.”
The team’s work is a part of the ICTD Lab’s goal to eventually create a cellular network that will allow people or organizations to deploy their own networks as easily as they do WiFi routers, where each network can come together to provide mutual roaming, which they call “cooperative cellular.” They are currently looking for non-profit organizations to help launch in Seattle, in addition to a King County Equity and Social Justice they recently received.
In addition to creating this open-sourced software and deploying it in communities that need it most, the group will also develop a STEM course called Community Networking. The course will give students an opportunity to explore the research, development and practice of access-related PIT and the partners and communities that are demonstrating an alternative viable path for a career in technology.
“Most of us take Internet access for granted to the point that, when the internet goes down, we struggle with continuing to get our work done,” said Allen School Director Magdalena Balazinska. “Yet some people, here in the United States, do not have such access. As computer scientists, we should always strive to solve important societal and world problems. I’m very excited about the way this project is using computer science to have a profound, positive impact on society.”
Pedro Domingos in the Paul G. Allen Center for Computer Science & Engineering. In his latest work, Domingos lifts the lid on the black box of deep learning. Dennis Wise/University of Washington
Deep learning has been immensely successful in recent years, spawning a lot of hope and generating a lot of hype, but no one has really understood why it works. The prevailing wisdom has been that deep learning is capable of discovering new representations of the data, rather than relying on hand-coded features like other learning algorithms do. But because deep networks are black boxes — what Allen School professor emeritus Pedro Domingos describes as “an opaque mess of connections and weights” — how that discovery actually happens is anyone’s guess.
Until now, that is. In a new paper posted on the preprint repository arXiv, Domingos gives us a peek inside that black box and reveals what is — and just as importantly, what isn’t — going on inside. Read on for a Q&A with Domingos on his latest findings, what they mean for our understanding of how deep learning actually works, and the implications for researchers’ quest for a “master algorithm” to unify all of machine learning.
You lifted the lid off the so-called black box of deep networks, and what did you find?
Pedro Domingos: In short, I found that deep networks are not as unintelligible as we thought, but neither are they as revolutionary as we thought. Deep networks are learned by the backpropagation algorithm, an efficient implementation for neural networks of the general gradient descent algorithm that repeatedly tweaks the network’s weights to make its output for each training input better match the true output. That process helps the model learn to label an image of a dog as a dog, and not as a cat or as a chair, for instance. This paper shows that all gradient descent does is memorize the training examples, and then make predictions about new examples by comparing them with the training ones. This is actually a very old and simple type of learning, called similarity-based learning, that goes back to the 1950s. It was a bit of a shock to discover that, more than half a century later, that’s all that is going on in deep learning!
Deep learning has been the subject of a lot of hype. How do you think your colleagues will respond to these findings?
PD: Critics of deep learning, of which there are many, may see these results as showing that deep learning has been greatly oversold. After all, what it does is, at heart, not very different from what 50-year-old algorithms do — and that’s hardly a recipe for solving AI! The whole idea that deep learning discovers new representations of the data, rather than relying on hand-coded features like previous methods, now looks somewhat questionable — even though it has been deep learning’s main selling point.
Conversely, some researchers and fans of deep learning may be reluctant to accept this result, or at least some of its consequences, because it goes against some of their deepest beliefs (no pun intended). But a theorem is a theorem. In any case, my goal was not to criticize deep learning, which I’ve been working in since before it became popular, but to understand it better. I think that, ultimately, this greater understanding will be very beneficial for both research and applications in this area. So my hope is that deep learning fans will embrace these results.
So it’s a good news/bad news scenario for the field?
PD: That’s right. In “The Master Algorithm,” I explain that when a new technology is as pervasive and game-changing as machine learning has become, it’s not wise to let it remain a black box. Whether you’re a consumer influenced by recommendation algorithms on Amazon, or a computer scientist building the latest machine learning model, you can’t control what you don’t understand. Knowing how deep networks learn gives us that greater measure of control.
So, the good news is that it is now going to be much easier for us to understand what a deep network is doing. Among other things, the fact that deep networks are just similarity-based algorithms finally helps to explain their brittleness, whereby changing an example just slightly can cause the network to make absurd predictions. Up until now, it has puzzled us why a minor tweak would, for example, lead a deep network to suddenly start labeling a car as an ostrich. If you’re training a model for a self-driving car, you probably don’t want to hit either, but for multiple reasons — not least, the predictability of what an oncoming car might do compared to an oncoming ostrich — I would like the vehicle I’m riding in to be able to tell the difference.
But these findings could be considered bad news in the sense that it’s clear there is not much representation learning going on inside these networks, and certainly not as much as we hoped or even assumed. How to do that remains a largely unsolved problem for our field.
If they are essentially doing 1950s-style learning, why would we continue to use deep networks?
PD: Compared to previous similarity-based algorithms such as kernel machines, which were the dominant approach prior to the emergence of deep learning, deep networks have a number of important advantages.
One is that they allow incorporating bits of knowledge of the target function into the similarity measure — the kernel — via the network architecture. This is advantageous because the more knowledge you incorporate, the faster and better you can learn. This is a consequence of what we call the “no free lunch” theorem in machine learning: if you have no a priori knowledge, you can’t learn anything from data besides memorizing it. For example, convolutional neural networks, which launched the deep learning revolution by achieving unprecedented accuracy on image recognition problems, differ from “plain vanilla” neural networks in that they incorporate the knowledge that objects are the same no matter where in the image they appear. This is how humans learn, by building on the knowledge they already have. If you know how to read, then you can learn about science much faster by reading textbooks than by rediscovering physics and biology from scratch.
Another advantage to deep networks is that they can bring distant examples together into the same region, which makes learning more complex functions easier. And through superposition, they’re much more efficient at storing and matching examples than other similarity-based approaches.
Can you describe superposition for those of us who are not machine learning experts?
PD: Yes, but we’ll have to do some math. The weights produced by backpropagation contain a superposition of the training examples. That is, the examples are mapped into the space of variations of the function being learned and then added up. As a simple analogy, if you want to compute 3 x 5 + 3 x 7 + 3 x 9, it would be more efficient to instead compute 3 x ( 5 + 7 + 9) = 3 x 21. The 5, 7 and 9 are now “superposed” in the 21, but the result is still the same as if you separately multiplied each by 3 and then added the results.
The practical result is that deep networks are able to speed up learning and inference, making them more efficient, while reducing the amount of computer memory needed to store the examples. For instance, if you have a million images, each with a million pixels, you would need on the order of terabytes to store them. But with superposition, you only need an amount of storage on the order of the number of weights in the network, which is typically much smaller. And then, if you want to predict what a new image contains, such as a cat, you need to cycle through all of those training images and compare them with the new one. That can take a long time. With superposition, you just have to pass the image through the network once. That takes much less time to execute. It’s the same with answering questions based on text; without superposition, you’d have to store and look through the corpus, instead of a compact summary of it.
So your findings will help to improve deep learning models?
PD: That’s the idea. Now that we understand what is happening when the aforementioned car suddenly becomes an ostrich, we should be able to account for that brittleness in the models. If we think of a learned model as a piece of cheese and the failure regions as holes in that cheese, we now understand better where those holes are, and what their shape and size is. Using this knowledge, we can actively figure out where we need new data or adjustments to the model to fix the holes. We should also improve our ability to defend against attacks that cause deep networks to misclassify images by tweaking some pixels such that they cause the network to fall into one of those holes. An example would be attempts to fool self-driving cars into misrecognizing traffic signs.
What are the implications of your latest results in the search for the master algorithm?
PD: These findings represent a big step forward in unifying the five major machine learning paradigms I described in my book, which is our best hope for arriving at that universal learner, what I call the “master algorithm.” We now know that all learning algorithms based on gradient descent — including but not limited to deep networks — are similarity-based learners. This fact serves to unify three of the five paradigms: neural, probabilistic, and similarity-based learning. Tantalizingly, it may also be extensible to the remaining two, symbolic and genetic learning.
Given your findings, what’s next for deep learning? Where does the field go from here?
PD: I think deep learning researchers have become too reliant on backpropagation as the near-universal learning algorithm. Now that we know how limited backprop is in terms of the representations it can discover, we need to look for better learning algorithms! I’ve done some work in this direction, using combinatorial optimization to learn deep networks. We can also take inspiration from other fields, such as neuroscience, psychology, and evolutionary biology. Or, if we decide that representation learning is not so important after all — which would be a 180-degree change — we can look for other algorithms that can form superpositions of the examples and that are compact and generalize well.
The American Association for the Advancement of Science, the world’s largest general scientific society, has named Allen School professor emeritus Pedro Domingos and professor Daniel Weld among its class of 2020 AAAS Fellows honoring members whose scientifically or socially distinguished efforts have advanced science or its applications. Both Domingos and Weld were elected Fellows in the organization’s Information, Computing, and Communication section for their significant impact in artificial intelligence and machine learning research.
Domingos was honored by the AAAS for wide-ranging contributions in AI spanning more than two decades and 200 technical publications aimed at making it easier for machines to discover new knowledge, learn from experience, and extract meaning from data with little or no help from people. Prominent among these, to his AAAS peers, was his introduction of Markov logic networks unifying logical and probabilistic reasoning. He and collaborator Matthew Richardson (Ph.D., ‘04) were, in fact, the first to coin the term Markov logic networks (MLN) when they presented their simple yet efficient approach that combined first-order logic and probabilistic graphical models to support inference learning.
Domingos’ work has resulted in several other firsts that represented significant leaps forward for the field. He again applied Markov logic to good effect to produce the first unsupervised approach to semantic parsing — a key method by which machines extract knowledge from text and speech and a foundation of machine learning and natural language processing — in collaboration with then-student Hoifung Poon (Ph.D., ‘11). Later, Domingos worked with graduate student Austin Webb (M.S., ‘13) on Tractable Markov Logic (TML), the first non-trivially tractable first-order probabilistic language that suggested efficient first-order probabilistic inference could be feasible on a larger scale.
Domingos also helped launch a new branch of AI research focused on adversarial learning through his work with a team of students on the first algorithm to automate the process of adversarial classification, which enabled data mining systems to adapt in the face of evolving adversarial attacks in a rapid and cost-effective way. Among his other contributions was the Very Fast Decision Tree learner (VFDT) for mining high-speed data streams, which retained its status as the fastest such tool available for 15 years after Domingos and Geoff Hulten (Ph.D., ‘05) first introduced it.
In line with the AAAS’ mission to engage the public in science, in 2015 Domingos published The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World. Geared to the expert and layperson alike, the book offers a comprehensive exploration of how machine learning technologies influence nearly every aspect of people’s lives — from what ads and social posts they see online, to what route their navigation system dictates for their commute, to what movie a streaming service suggests they should watch next. It also serves as a primer on the various schools of thought, or “tribes,” in the machine learning field that are on a quest to find the master algorithm capable of deriving all the world’s knowledge from data.
Prior to this latest honor, Domingos was elected a Fellow of the Association for the Advancement of Artificial Intelligence (AAAI) and earned two of the highest accolades in data science and AI: the SIGKDD Innovation Award from the Association of Computing Machinery’s Special Interest Group on Knowledge Discovery and Data Mining, and the IJCAI John McCarthy Award from the International Joint Conference on Artificial Intelligence.
AAAS recognized Weld for distinguished contributions in automated planning, software agents, crowdsourcing, and internet information extraction during a research career that spans more than 30 years. As leader of the UW’s Lab for Human-AI Interaction, Weld seeks to combine human and machine intelligence to accomplish more than either could on their own. To that end, he and his team focus on explainable machine learning, intelligible and trustworthy AI, and human-AI team architectures to enable people to better understand and control AI-driven tools, assistants, and systems.
Weld has focused much of his career on advanced intelligent user interfaces for enabling more seamless human-machine interaction. Prominent among these is SUPPLE, a system he developed with Kryzstof Gajos (Ph.D., ‘08) that dynamically and optimally renders user interfaces based on device characteristics and usage patterns while minimizing user effort. Recognizing the potential for that work to improve the accessibility of online tools for people with disabilities, the duo subsequently teamed up with UW Information School professor and Allen School adjunct professor Jacob Wobbrock to extend SUPPLE’s customization to account for a user’s physical capabilities as well.
Another barrier that Weld has sought to overcome is the amount of human effort required to organize and maintain the very large datasets that power AI applications. To expedite the process, researchers turned to crowdsourcing, but the sheer size and ever-changing nature of the datasets still made it labor-intensive. Weld, along with Jonathan Bragg (Ph.D., ‘18) and affiliate faculty member Mausam (Ph.D., ‘07), created Deluge to optimize the process of multi-label classification that significantly reduced the amount of labor required compared to the previous state of the art without sacrificing quality. Quality control is a major theme of Weld’s work in this area, which has yielded new tools such as Sprout for improving task design, MicroTalk and Cicero for augmenting decision-making, and Gated Instruction for more accurate relation extraction.
In addition to his technical contributions, AAAS also cited Weld’s impact via the commercialization of new AI technologies. During his tenure on the UW faculty, he co-founded multiple venture-backed companies based on his research: Netbot Inc., creator of the first online comparison shopping engine that was acquired by Excite; AdRelevance, an early provider of tools for monitoring online advertising data that was acquired by Nielsen Netratings; and Nimble Technology, a provider of business intelligence software that was acquired by Actuate. Weld has since gone from founder to funder as a venture partner and member of the Technology Advisory Board at Madrona Venture Group.
Weld, who holds the Thomas J. Cable/WRF Professorship, presently splits his time between the Allen School, Madrona, and the Allen Institute for Artificial Intelligence (AI2), where he directs the Semantic Scholar research group focused on the development of AI-powered research tools to help scientists overcome information overload and extract useful knowledge from the vast and ever-growing trove of scholarly literature. Prior to this latest recognition by AAAS, Weld was elected a Fellow of both the AAAI and the ACM. He is the author of roughly 200 technical papers and two books on AI on the theories of comparative analysis and planning-based information agents, respectively.
Domingos and Weld are among four UW faculty members elected as AAAS Fellows this year. They are joined by Eberhard Fetz, a professor in the Department of Physiology & Biophysics and DXARTS who was honored in the Neuroscience section for his contributions to understanding the role of the cerebral cortex in controlling ocular and forelimb movements as well as motor circuit plasticity, and Daniel Raftery, a professor in UW Medicine’s Department of Anesthesiology and Pain Medicine who was honored in the Chemistry section for his contributions in the fields of metabolomics and nuclear magnetic resonance, including advanced analytical methods for biomarker discovery and cancer diagnosis.
The robust impact that the Allen School and the University of Washington have in contributing to accessible technology was recognized at the 22nd International ACM SIGACCESS Conference on Computer and Accessibility (ASSETS 2020) held virtually last month. Researchers from the Allen School and the UW contributed to the Best Student Paper, Best Artifact and the Best Paper.
A team led by UW Human Centered Design & Engineering alumna and Carnegie Mellon University postdoc Cynthia Bennett earned the Best Student Paper Award for Living Disability Theory: Reflections on Access, Research and Design. The paper was co-written by lead author Megan Hoffman, a Ph.D. student at CMU, along with Allen School professor Jennifer Mankoff and City University of New York professor Devva Kasnitz. The paper emphasizes the importance of integrating disability studies perspectives and disabled people into accessibility research.
Top left to right: Mankoff, Froehlich, Jain Bottom left to right: Patel, Ngo, Nguyen
In the paper, the authors correlate personal experiences with theoretical experiences. They found that while accessibility research tends to focus on creating technology related to impairment, without including disability studies — which seeks to understand disability and advocate against ableist systems — accessibility research isn’t as inclusive as its intended purpose. From their research and personal experiences, the authors exemplify how disability is often mired in ableism and oversimplified. They urge disability researchers to commit to recognizing and repairing ableism; study disability beyond diagnosis; incorporate a disability studies perspective that includes disabled voices; and incorporate reflexive, interpretivist study as a regular and essential practice.
“It was so inspiring to learn from and be part of the team writing this paper,” said Mankoff, who leads the Allen School’s Make4All group. “More than anything it showed me that the next generation of scholars are already leading the way in defining what matters in our scholarship.”
Members of the Allen School also contributed to the Best Artifact: SoundWatch, a smartwatch app for d/Deaf and hard-of-hearing people who want to be aware of nearby sounds. The creators are Allen School Ph.D. student and lead author Dhruv Jain, Pratyush Patel and professor Jon Froehlich; undergraduates Hung Ngo and Khoa Nguyen; HCDE professor and Allen School adjunct professor Leah Findlater; Ph.D. student Steven Goodman; and research scientist Rachel Grossman-Kahn.
SoundWatch is an app for Android smartwatches that uses machine learning to alert users of sounds like nearby fire alarms and beeping microwaves, making their environment more accessible. Soundwatch identifies the sound and alerts the user with a friendly buzz along with information about the sound on the screen of the watch.
“This technology provides people with a way to experience sounds that require an action — such as getting food from the microwave when it beeps. But these devices can also enhance people’s experiences and help them feel more connected to the world,” said Jain in a recent UW News release. “I use the watch prototype to notice birds chirping and waterfall sounds when I am hiking. It makes me feel present in nature. My hope is that other d/Deaf and hard-of-hearing people who are interested in sounds will also find SoundWatch helpful.”
“The University of Washington has been a leader in accessible technology research, design, engineering, and evaluation for years,” said iSchool professor and Allen School adjunct professor Jacob O. Wobbrock, who, along with Mankoff, serves as founding co-director of the UW’s Center for Research and Education on Accessible Technology and Experiences (CREATE).”This latest round of awards from ACM ASSETS is further testament to the great work being done at the UW. Now, with the recent launch of CREATE, our award-winning faculty and students are brought together like never before, and we are already seeing the great things that come of it.”
Congratulations to all of the ASSETS 2020 award recipients!
Robots have traditionally been deployed for dull, dirty or dangerous tasks. What if robots instead could be used to support the sophisticated and iterative work of domain experts such as chemical engineers or synthetic biologists?
A University of Washington research project led by Allen School adjunct faculty member and Human-Centered Design and Engineering professor Nadya Peek and Allen School and Electrical and Computer Engineering professor Josh Smith, “NRI: FND: Multi-Manipulator Extensible Robotic Platforms,” received a $700,000 grant from the National Science Foundation’s (NSF) National Robotics Initiative 2.0: Ubiquitous Collaborative Robots (NRI-2.0) program.
“The tools we propose to develop include a family of open-source, replicable, extensible, parametrically-defined co-bots that will enable experts to iteratively develop automated processes and experiments,” Peek said. “This grant will help us develop hardware and software for authoring, running, and verifying automated workflows.”
Smith’s lab has developed an ultrasonic manipulator that allows a robot to pick up small objects without touching them. The grant will allow the researchers to combine this new ultrasonic manipulator with Peek’s open source multi-tool motion platforms, including Jubilee.
“Non-contact manipulation can allow robots to pick up small objects and powders, which is currently challenging for robots,” Smith said. “Non-contact manipulation can also help maintain sterility, which could be useful in surgical settings, and any time we are concerned about spreading pathogens.”
The integrated robotic system will allow end-users to develop automated workflows for domain specific tasks. The researchers are designing their system to be customizable and extensible. In particular, the robotic systems they develop are fabricatable, meaning that they can be made with easily sourced parts or parts made using low cost digital fabrication tools such as 3D printers. This means that even when the domain experts create highly sophisticated interactive and automated workflows, their experimental setups can easily be reproduced by other scientists.
In honor of the National First-Generation College Celebration on November 8, our latest Allen School spotlight highlights some of our own first-gen community members. Approximately 20 percent of the school’s undergraduate student body is the first in their family to pursue a four-year degree. Each is an academic trailblazer, navigating their way through the entire college experience as the first in their family to pursue a bachelor’s degree. Some are still finding their footing with the help of Gen1, a new student group for first-gen students, while others have been there, done that. These folks were eager to share what they have learned along the way.
Jun Hu, undergraduate student
Jun Hu
Jun Hu is a transfer student from Everett Community College originally from Canton, China. He moved to the United States in 2007, when he was 18. His interest in computer science began when his uncle, a computer software engineer, stayed with his family while Hu was in high school. When he moved to the U.S., Hu joined the Navy. While serving in the military, his interest in computer science grew as he noticed the constraints of the programs he was using and wanted to do something about it.
Allen School: As a first-generation student in a new country, how did you navigate through the college system?
Jun Hu: I went to college in China very briefly after high school — though the college experience was quite different compared to the states. Here you have so much freedom both socially and academically. I was quite lost. I did not know my education plan and just how life goes in general. Luckily, my adviser gave me a degree plan and it cleared up a bit. That was the first time I went to college after I moved to the states. After that, I took several classes when I was in the Navy, and the experience I learned from that helped me a lot. I was enrolled at Everett Community College but decided to transfer to the UW. I chose to do this because the CSE program in the Allen School is decent and there are a lot of resources and extracurricular activities to help you succeed.
Allen School: What does being a first-gen student mean to you?
JH: As a first-generation student, I felt it could be challenging sometimes because there is not much information you can obtain from your parents about college life in general. It is just a new experience that you have to go through on your own and figure things out along the way.
Allen School: What is your favorite part about being in the Allen School?
JH: It has been a pleasure to work with the advising team from the Allen school. Despite having been to several colleges, transferring to a new university is still difficult because each school has its own system on handling registration and navigating around the campus. Luckily, my adviser has been working with me since I got accepted so it made the transaction much easier. The teaching assistants and office hours in my classes are extremely helpful for me this quarter because the difficulty of the classes is much higher and online learning has created more barriers for me.
Allen School: What advice do you have for future first-gen students?
JH: The most important advice I have is to reach out for help. You are not alone in this process, there is a lot of help and opportunity for students to succeed. Most of the schools even have programs for first-gen students. The academic adviser is your friend. They will provide you some pathway when you are not sure what to do. The tutoring center is a fun place to hang out. You are able to get help with your school work and maybe meet some new friends that are also studying your field. Also, don’t be afraid to make mistakes and go explore new things. Join a student organization or be part of the student government and get involved. College is not only a place to obtain higher education, but also a place to know more about yourself. You will be surprised that you have more talents than you thought. By doing something you may find new goals and figure out what you really want to do.
Eman Mustefa, undergraduate student
Eman Mustafa
As a child of immigrants, Eman Mustefa, a sophomore from Federal Way, Washington, said she was expected to go to college. Her mother, who briefly attended community college, supported her in every way she could, despite not knowing much about the college process in the United States. Growing up in western Washington, Mustefa knew as early as second grade that she wanted to attend the UW. With an interest in technology and computers, and a few hours of programming under her belt from attending “Hour of Code” days in high school, her choice was to enroll in the Allen School.
Allen School: As a first-generation student, how did you navigate through the college system?
Eman Mustefa: I was very overwhelmed at first because I had not thought much about applying to college until the very end of my junior year. It felt like all of my other classmates had been prepping since the first day of high school, and I hadn’t done that at all. Luckily I had a really strong support system. My cousin was an instrumental part during my college application process. She was in her last year of college and was able to guide me to some of the resources that helped her and revise most of my essays. My aunt and uncle were also very supportive and along with my mom, they all took turns dropping me off and picking me up at every tour, testing location and interview. Although my mom knew she couldn’t help me with many parts of the process, she helped in any way that she could.
Allen School: What does being a first-gen student mean to you?
EM: Being a first-generation graduate means thanking my family for all the support and encouragement that they have given to me throughout the years, and showing them it was all worth it. It means showing others from first-generation backgrounds that it is possible and you don’t have to be a “traditional computer science student” in order to succeed in the field.
Allen School: What is your favorite part about being in the Allen School?
EM: My favorite part about working and being at the Allen School is hearing about everyone’s various backgrounds. I think in many people’s minds when we hear computer science we think about a monolith but in reality, each person that goes here is so different.
Allen School:What advice do you have for future first-gen students?
EM: I would tell them that even though it may feel like you are alone, you are not. There are so many different communities and people in the Allen School that are here for you, GEN1, a club I founded with a couple of my friends last year for first-generation college students, was made for that very reason. So know that you have a support system, even when it feels tough and it’s impossible, they are there to cheer you on to keep going.
Joyce Zhou, master’s student
Joyce Zhou
As a high school student, Joyce Zhou was accepted into the UW Academy, an early university admission opportunity for 10th grade students in Washington. They enjoyed their computer science classes in high school and had a great Advanced Placement computer science teacher, so it was only natural for them to continue their studies at the UW. After a successful undergraduate experience, they decided to continue as a graduate student in the Allen School’s fifth-year master’s program, working with professor Daniel Weld in the Lab for Human-AI Interaction.
Allen School: As a first-gen student, how did you navigate through the application and enrollment process?
Joyce Zhou: Because I got into the UW Academy, I was lucky not to have to navigate the entire college search process, just the requirements for applying to UW only. That still meant taking the SAT/ACT and writing several application essays, though. The Robinson Center provided lots of materials that described what to expect from the process. My parents, being Chinese, are super familiar with the idea of preparing for exams so I was set on test prep and high school grades, but for personal statement writing I used a lot of online guides.
Once I actually got into college, I learned from other people in my Academy cohort how to handle coursework. Online forums like Reddit were also really good for answering questions about undergraduate research and how to get involved. Unfortunately, I never got as familiar with the social part of college — such as networking and transitioning to adulthood — so I’m still struggling today with that. There’s been tons of helpful people along the way: high school teachers, advisers, TAs and resident assistants.
Allen School: What is your favorite part about being in the Allen School?
JZ: The people! Maybe I’m biased because I’m a grad student now, but I love that within the school it’s such a casual environment. There’s the openness between instructors, TAs, and students, tiny fun things that people pin up on lab windows or room number cork boards, events preceded by friendly jokes. Also the part where the actual people I know and talk frequently with are cool and do cool things.
Allen School: What advice do you have for future first-gen students?
JZ: Get to know people, as much of a wide range of people as possible — fellow first-gen students, grad students, advisers — and build or join some sort of friend support group. Also, don’t be afraid to ask questions or lurk on online forums as well, if there’s a question you have about how college works it’s almost certain someone has answered it online before.
Elise deGoede Dorough, staff
Elise deGoede Dorough
Elise deGoede Dorough, originally of Sumner, Washington, is the Allen School’s director of graduate student services. Her grandparents, who immigrated from the Netherlands, met in western Washington and started TulipTown, a tulip bulb farm in Mt. Vernon. While her father went into the family business after high school, he wanted deGoede Dorough and her brother to have other options and encouraged them to go to college. She relied on teachers and peers to coach her through which classes to pick and which standardized tests to take. In the end, the UWwas the only school she applied to, as it was the only in-state school she was interested in attending.
Allen School: Did being a first-gen student influence your career?
Elise deGoede Dorough: I think it did influence my career. As an undergraduate, the UW was so big to me. When I look back, I realize that I needed more support but really didn’t know where to find it. Especially as a pre-major, I didn’t know who I could talk to about which major to pursue and how I should be preparing for different career paths. I also worked nearly full-time as a server in a restaurant from the summer of my freshman year all through the remainder of college, so I didn’t have a ton of extra time for any kind of exploration. My freshman year I ended up earning a 4.0 in my psychology class so I eventually chose that as my major without ever speaking to a staff adviser or a faculty member.
I was an introvert and maybe because of that I always first tried to find the information I needed online. So I read up on the course requirements, processes for declaring a major, etc. and submitted the paperwork. By the time I graduated I had probably only seen a staff adviser about three times in total. At that point, I had no idea that becoming an academic adviser, or working in student affairs in general, was a possible career path. I spent some years after college as a manager in the same restaurant I worked in through college, before I realized that I missed the rhythm of the academic year and I missed being on campus. I didn’t know what I would go back to school for, so instead I applied to fill in temp staff roles around campus. It was through those experiences that I realized working as a staff member for the UW was a possibility for me. Eventually I took an admissions and recruiting position at another college and went back to school for my Master’s in Education at the UW. Near the end of that program I was hired as an undergraduate adviser at the Allen School, and 10 years later here I am.
Allen School: What does being a first-gen student mean to you?
E dD: I would say opportunity and freedom to choose. Some people ask me why I didn’t go into the family business, and the answer is not because it wasn’t a good option. My dad and my younger brother, after going to college himself, are farming together now. I believe that our parents’ insistence that we both go to college and then make the choice of whether to join the family business or not was a good one. It gave us more time to learn what was out there and what we enjoyed doing. And it gave us the knowledge that we were in control of our path.
Allen School: What does working at the Allen School mean to you?
E dD: It might seem odd because I don’t have a background in computer science, but the Allen School is where I’ve really felt at home on the UW campus. I enjoyed my time as a student, and as I mentioned I love the rhythm of the academic year. But I never felt I had a specific home at UW even within the departments where I earned my degrees. I always felt anonymous and a little bit like an outsider, unsure of where my value or contributions were. But in CSE, as we called it when I joined, I have found ways to really make an impact, support students, and find fulfillment in that work.
Allen School: What advice do you have for future first-gen students?
E dD: Ask people where the resources are! I was so introverted and I thought I had to figure it out on my own. But there are people everywhere — peers, staff, faculty — who are more than willing to hear your questions and point you in the right direction. It can be very intimidating at first and students often apologize to me for asking questions. But, really, it’s my job to help and helping in that way is why I’m here.
Zachary Tatlock, professor
Zachary Tatlock
Allen School professor Zachary Tatlock grew up in a small southern Indiana town, where both of his parents also grew up. His father worked as a machinist and, after raising four children, his mother worked as a special education aide. His parents were supportive of his choice to go to college, but it was made clear that he would have to work hard and get a good scholarship. He did, which enabled him to enroll in Purdue University. Paging through the university’s booklet of majors, he chose computer science because it “sounded kind of like math but where you got to actually tinker and make things.”
Allen School: Why did you decide to continue your education and also become an educator yourself?
Zachary Tatlock: At Purdue I made some truly spectacular friends who had seemingly been programming since shortly after they started walking, while I knew relatively zip. I was again lucky that the community at Purdue was extremely supportive and helped a kid like me get up to speed. After my first year, I wanted to give back somehow, so I started TAing lab sessions for the introductory Java programming course. That went pretty well, and after a couple semesters I was put in charge of all the labs. I got to hire the friends who had helped me during my early struggles and we spent the next couple of years having a blast trying out all kinds of experiments, making new lab material and teaching it, and holding extra office hours late at night before project deadlines. I just couldn’t imagine leaving the academic computer-science community after only four years, so I decided to pursue a Ph.D. I wanted to make a career of hacking on interesting, diverse projects with brilliant friends from all over the world and helping share the joy of programming with students.
I was inspired by superb mentors like my undergraduate advisor, Suresh Jagannathan, who taught me that who you work with is more important than any particular project details, and my utterly amazing Ph.D. advisor, Sorin Lerner, taught me that academic research goes best when you put students first.
Allen School: What does being a first-gen student mean to you?
ZT: Being a first-generation student has meant bridging cultures, and more so the further I’ve gone down the academic path. Folks back home often don’t have much context to appreciate what researchers are doing with their hard-earned tax money; it can be difficult to convincingly justify why you and your friends worked hard for a year and then stayed up late for two weeks straight to make a piece of software that primarily exists just to be evaluated in a research paper. On the academic side, research colleagues often don’t have much context to appreciate the culture and norms of rural towns or so-called flyover states. In practice, it’s usually been best to just listen to folks and occasionally ask patient questions to help them hear what their ideas about “the other side” might sound like from a different perspective. Getting a college education has also provided other important, though more prosaic, benefits, like improving my ability to help support my family.
I also know that I have been unaccountably fortunate to end up with the career I’m in. I hope to pay it forward and smooth the way for other students who may not have had a clear path towards college or computer science.
Allen School: What do you like most about working at the Allen School?
ZT: The students are the very best part of the Allen School. Their enthusiasm, creativity, and incredible work ethic make every day a joy. I am also lucky to have some amazing colleagues who continue to challenge us all to grow and get better year after year. I love that I get to tackle new problems, meet new people, and learn new skills almost every day — this is a job that will never get boring. The Allen School culture weaves all these pieces together in a vibrant, close-knit community that cares a lot about young people; though Seattle is not a small town the Allen School feels like home.
Allen School: What advice do you have for future first-gen students?
ZT: Pay attention and be persistent! If you keep your wits about you and just keep going no matter how bad things look, you will often succeed. Even if you don’t win a particular battle, you will know that you have done your best and you will have learned some valuable lessons. I know that all sounds trite, but the fact is that many people who don’t make it just over-worry and overthink themselves out of success. Another thing to always remember is that you belong: even though many of your fellow students will have had very different upbringings and opportunities, college is especially for people like you.
We are grateful for the many contributions our first-generation students, staff and faculty have made to our campus and community!
Ximing Lu (left) and Sanjana Chintalapati were recognized during the virtual Diversity in Computing celebration hosted by the Allen School last week
Kicking off the fall quarter by celebrating diversity in computing has become an Allen School tradition. This year the celebration went virtual, with around 80 people logged on to honor students who embody the school’s commitment to diversity and excellence and to hear from members of the community who participated in the Grace Hopper Celebration, the world’s largest gathering of women technologists, and the ACM Richard Tapia Celebration of Diversity in Computing, which brings together people of all backgrounds, abilities and genders in computing.
Allen School director Magdalena Balazinska welcomed participants to the celebration by highlighting some of the programs the Allen School has invested in to increase diversity, equity and inclusion, For example, the school has partnered with the College of Engineering’s STARS program and AccessCSForAll in order to nurture promising talent to bring to the Allen School and the field of computing. Balazinska also highlighted three student-led groups focused on supporting a diverse and inclusive community: Minorities in Tech (MiT), Gen1 and Q++. Following Balazinska’s remarks, professor Tadayoshi Kohno, the school’s associate director for diversity, equity and inclusion, spoke about new high school and summer programs the school is creating to find more students having diverse backgrounds and experiences. Other actions include conducting faculty searches at more diverse research institutions and posting open staff positions on more inclusive job posting websites.
During the diversity celebration, in a panel discussion hosted by Les Sessoms, The Allen School’s recruitment and retention specialist, Ph.D. student Samia Ibtasam in the Information and Communication Technology for Development Lab, and undergraduates Ximing Lu and Marisa Radensky talked about their initial interest in studying computer science and about their positive experiences at the conferences. Ibtasam said it was an inspiring experience to see other students like her represented at Grace Hopper, explaining that she felt like she was home. Each of the panelists felt the conferences opened up new opportunities that they didn’t know were available to them.
In addition to serving on the panel, Lu was recognized with the Lisa Simonyi Prize. Longtime friends of the school Lisa and Charles Simonyi established the scholarship to recognize and support students who exemplify excellence, leadership, and diversity. Lu, who is a double major in computer science and statistics, is a highly accomplished researcher. She has worked with Allen School and Electrical & Computer Engineering professor Linda Shapiro on the automated classification of cancer biopsy images; Allen School professor Yejin Choi on natural language generation; and Allen School professor Kevin Jamieson and Materials Science & Engineering professor Mehmet Sarikaya on neural network approaches for molecular analysis. She has also been a software developer with the Avionics Team of the UW Society for Advanced Rocket Propulsion, and with the UW Sensors, Energy and Automation Laboratory.
“Ximing has had a busy undergraduate career, earning a high GPA taking both undergraduate and graduate classes, interning, and working on several research projects,” Shapiro said. “I’m happy to see her hard work is paying off.”
“Ximing is hands down the best and the most promising undergraduate student I’ve ever seen or worked with over the past six years since I arrived at the University of Washington,” said Choi. “Not only is she extremely fast and technically strong, which I’ve seen before a few times, but she’s bursting with creative ideas, which is very rare. She also has enormous energy and enthusiasm for research at all levels of execution, which is even less common.”
Sanjana Chintalapati, a junior studying computer science, was awarded the Allen AI Outstanding Engineer Scholarship for Women and Underrepresented Minorities from the Allen Institute for Artificial Intelligence (AI2). The scholarship was created to encourage students from underrepresented groups to excel in computer science and engineering and become leaders and role models in their fields.
“Sanjana discovered something we try to emphasize: that success in computer science is much more dependent on committing oneself to constant learning and much less dependent on having a natural knack for it,” Balazinska said.
Chintalapati is interested in accessibility and is currently working on multiple projects that use computing to assist people with disabilities, including an app that assists disabled users who are using transit stations. The app is designed to alert users when an elevator is out of service that would prevent them from accessing the train or bus. Allen School professor emeritus Oren Etzioni, the CEO of AI2, said during the program that in an imposing field of applicants for the scholarship, Chantalapati stood out. The selection committee could tell how passionate she is about using technology for good, which Etzioni noted aligns well with the mission of AI2.
Thanks to the Simonyis and AI2 for supporting diversity and excellence, and thanks to everyone who logged on to celebrate the people who are making our school and our field a more welcoming destination for all. And congratulations to Ximing and Sanjana!
For more about the Allen School’s efforts to advance diversity in computing, please visit our website.
Many people have had the experience of being poked in the back by those annoying plastic tags while trying on clothes in a store. That is just one example of radio frequency identification (RFID) technology, which has become a mainstay not just in retail but also in manufacturing, logistics, transportation, health care, and more. And who wouldn’t recognize the series of black and white lines comprising that old grocery-store standby, the scannable barcode? That invention — which originally dates back to the 1950s — eventually gave rise to the QR code, whose pixel patterns serve as a bridge between physical and digital content in the smartphone era.
Despite their near ubiquity, these object tagging systems have their shortcomings: they may be too large or inflexible for certain applications, they are easily damaged or removed, and they may be impractical to apply in high quantities. But recent advancements in DNA-based data storage and computation offer new possibilities for creating a tagging system that is smaller and lighter than conventional methods.
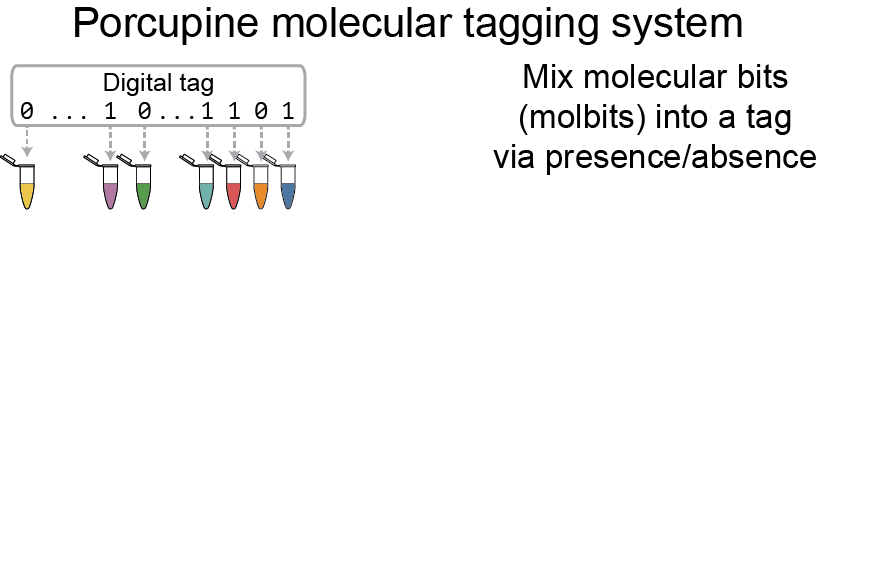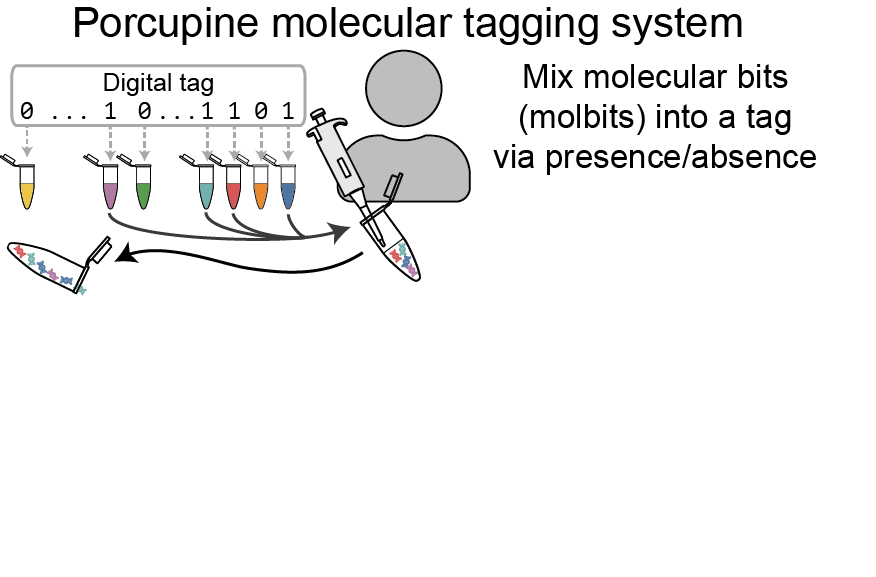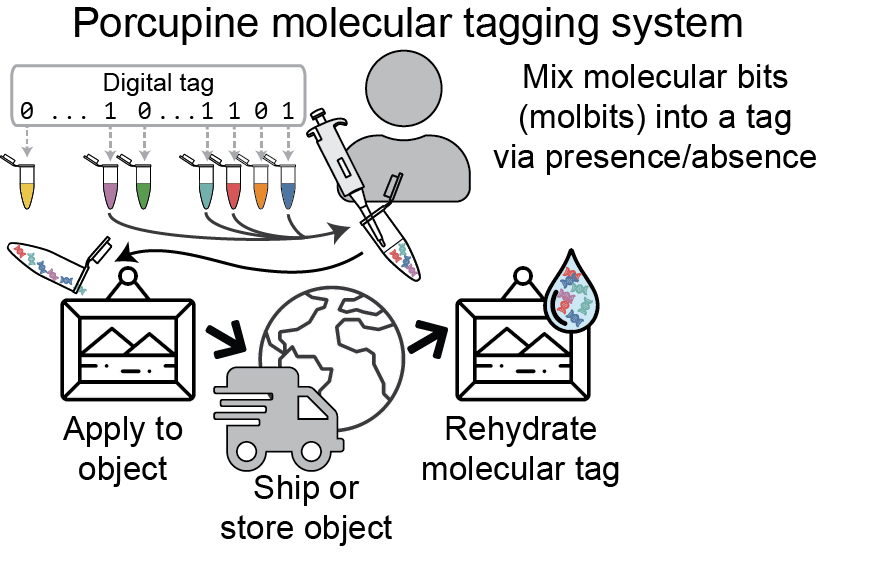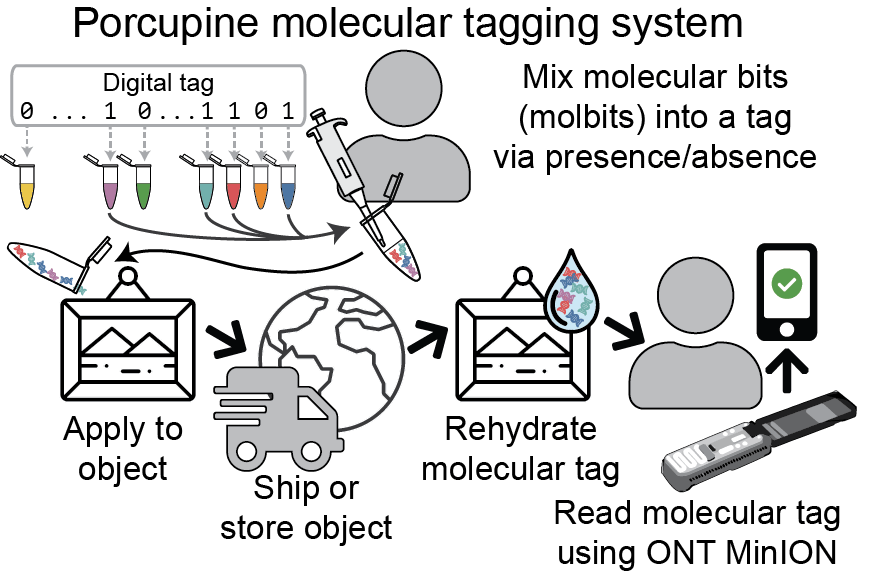
That’s the point of Porcupine, a new molecular tagging system introduced by University of Washington and Microsoft researchers that can be programmed and read within seconds using a portable nanopore device. In a new paper published in Nature Communications, the team in the Molecular Information Systems Laboratory (MISL) describe how dehydrated strands of synthetic DNA can take the place of bulky plastic or printed barcodes. Building on recent developments in nanopore-based DNA sequencing technologies and raw signal processing tools, the team’s inexpensive and user-friendly design eschews the need for access to specialized labs and equipment.
“Molecular tagging is not a new idea, but existing methods are still complicated and require access to a lab, which rules out many real-world scenarios,” said lead author Kathryn Doroschak, a Ph.D. student in the Allen School. “We designed the first portable, end-to-end molecular tagging system that enables rapid, on-demand encoding and decoding at scale, and which is more accessible than existing molecular tagging methods.”
Instead of radio waves or printed lines, the Porcupine tagging scheme relies on a set of distinct DNA strands called molbits — short for molecular bits — that incorporate highly separable nanopore signals to ease later readout. Each individual molbit comprises one of 96 unique barcode sequences combined with a longer DNA fragment selected from a set of predetermined sequence lengths. Under the Porcupine system, the binary 0s and 1s of a digital tag are signified by the presence or absence of each of the 96 molbits.
“We wanted to prove the concept while achieving a high rate of accuracy, hence the initial 96 barcodes, but we intentionally designed our system to be modular and extensible,” explained MISL co-director Karin Strauss, senior principal research manager at Microsoft Research and affiliate professor in the Allen School. “With these initial barcodes, Porcupine can produce roughly 4.2 billion unique tags using basic laboratory equipment without compromising reliability upon readout.”
Although DNA is notoriously expensive to read and write, Porcupine gets around this by presynthesizing the fragments of DNA. In addition to lowering the cost, this approach has the added advantage of enabling users to arbitrarily mix existing strands to quickly and easily create new tags. The molbits are prepared for readout during initial tag assembly and then dehydrated to extend shelf life of the tags. This approach protects against contamination from other DNA present in the environment while simultaneously reducing readout time later.
Another advantage of the Porcupine system is that molbits are extremely tiny, measuring only a few hundred nanometers in length. In practical terms, this means each molecular tag is small enough to fit over a billion copies within one square millimeter of an object’s surface. This makes them ideal for keeping tabs on small items or flexible surfaces that aren’t suited to conventional tagging methods. Invisible to the naked eye, the nanoscale form factor also adds another layer of security compared to conventional tags.
The Porcupine team: (top, from left) Kathryn Doroschak, Karen Zhang, Melissa Queen, Aishwarya Mandyam; (bottom, from left) Karin Strauss, Luis Ceze, Jeff Nivala
“Unlike existing inventory control methods, DNA tags can’t be detected by sight or touch. Practically speaking, this means they are difficult to tamper with,” explained co-author Jeff Nivala, a research scientist at the Allen School. “This makes them ideal for tracking high-value items and separating legitimate goods from forgeries. A system like Porcupine could also be used to track important documents. For example, you could envision molecular tagging being used to track voters’ ballots and prevent tampering in future elections.”
To read the data in a Porcupine tag, a user rehydrates the tag and runs it through a portable Oxford Nanopore Technologies’ MinION device. To demonstrate, the researchers encoded and then decoded their lab acronym, “MISL,” reliably and within a few seconds using the Porcupine system. As advancements in nanopore technologies make them increasingly affordable, the team believes molecular tagging could become an increasingly attractive option in a variety of real-world settings.
“Porcupine is one more exciting example of a hybrid molecular-electronic system, combining molecular engineering, new sensing technology and machine learning to enable new applications.” said Allen School professor and MISL co-director Luis Ceze.
In addition to Ceze, Doroschak, Nivala and Strauss, contributors to the project include Allen School undergraduate Karen Zhang, master’s student Aishwarya Mandyam, and Ph.D. student Melissa Queen. This research was funded in part by the Defense Advanced Research Project Agency (DARPA) under its Molecular Informatics Program and gifts from Microsoft.
In the winning Test of Time paper, Heer and co-author Edward Segel explored how visual data enhances journalistic storytelling and studied design strategies for narrative visualization. The paper helped to frame and advance research into the use of visualization for journalistic reporting and storytelling. Since then, it has been widely cited and influential in the fields of both visualization and data-driven journalism.
Fascinated by the growing use of visualizations in online journalism, Heer and Segel built a catalog of examples to identify distinct genres of narrative visualization. The two characterized the design differences and messaging and found that many samples could be more dynamic with the help of more sophisticated online tools — including those that allow interactive exploration by the reader.
When the paper was originally published, Heer was a professor of computer science at Stanford University and Segel was a master’s student. Together, they created a comprehensive framework of design strategies for narrative visualization.
“We wanted to better understand the innovative work of data journalists and designers whose insights we hoped to give further reach with our paper,” Heer said. “From the framework of our research, we found promising yet under-utilized approaches to integrating visualization with other media, and the potential for improved user interfaces for crafting data stories.”
Heer had already started to develop a series of robust tools for producing interactive visualizations on the web. As a graduate student, he helped to create Prefuse, one of the first software frameworks for information visualization, and Flare, a version of Prefuse built for Adobe Flash that was partly informed by his work in animated transitions. This latest research with Segel focused on a central concern in the design of narrative visualizations: the balance between author-driven elements that provide narrative structure and messaging, and reader-driven elements that enable interactive exploration and social sharing. This work helped to identify successful design practices that guided the development of new narrative visualization tools.
Since joining the Allen School faculty in 2013, Heer has worked on a suite of complementary tools for data analysis and visualization design built on Vega, a declarative language for producing interactive visualizations. These tools include Lyra, an interactive environment for generating customized visualizations, and Voyager, a recommendation-powered visualization browser. In 2017 he was recognized with the IEEE Visualization Technical Achievement Award and the ACM Grace Murray Hopper Award for his significant technical contributions early in his career.
Vega led to Vega-Lite, a project that earned Heer and Moritz — now a professor in the Human-Computer Interaction Institute at Carnegie Mellon — a Best Paper Award at InfoVis 2016 along with their collaborators. Vega-Lite is a high-level grammar for rapid and concise specification of interactive data visualizations. The goal was to enable non-programmers to create sophisticated visualizations that can be generated automatically. That project and others formed the basis of Moritz’s 2019 dissertation, which made a number of contributions spanning formal languages, automatic reasoning for visualization design, and novel approaches for scaling interactive visualization to massive datasets for which he was honored at this year’s VIS conference.
One of those contributions was Draco, an open-source, constraint-based system that formalized guidelines for visualization design and their application in visualization tools. The system, which earned Moritz and his colleagues a Best Paper Award at InfoVis 2018, offers a one-stop shop for researchers and practitioners to apply and test a set of accepted design principles and preferences and to make adjustments to their visualizations based on the results. To expand the application of user-friendly visualization tools to larger datasets, Moritz introduced Pangloss, which enables analysts to interactively explore approximate results pending completion of long-running queries. Pangloss generates visualizations based on samples while queries are ongoing, with the ability to detect and correct errors later. Moritz followed that up with Falcon, a web-based system that supports real-time exploration of billion-record datasets by enabling low-latency interactions across linked visualizations.
Moritz’s interactive systems for visualization and analysis have seen widespread adoption in the Python and JavaScript communities.